![[GCP] Google Cloud Certified - Professional Cloud Developer](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_professional-cloud-developer-1200x675.jpg)
※ 他の問題集は「タグ:Professional Cloud Developer の模擬問題集」から一覧いただけます。
この模擬問題集は「Professional Cloud Developer Practice Exam (2021.04.04)」の回答・参考リンクを改定した日本語版の模擬問題集です。
Google Cloud 認定資格 – Professional Cloud Developer – 模擬問題集(全 84問)
Question 1
データ移行の一環として、オンプレミスの仮想マシンから Google Cloud Storage にファイルをアップロードを検討しています。
これらのファイルはGCP 環境の Google Cloud Dataproc Hadoop クラスタで利用されます。
どのコマンドを使うべきでしょうか?
- A. gsutil cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
- B. gcloud cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
- C. hadoop fs cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
- D. gcloud dataproc cp [LOCAL_OBJECT] gs://[DESTINATION_BUCKET_NAME]/
Correct Answer: A
gsutil cpコマンドはローカルファイルと「gsutil config」を実行して生成したストレージのbotoファイルの間でデータをコピーすることができます。
Reference contents:
– オブジェクトのアップロード | Cloud Storage
Question 2
アプリケーションを Google Cloud Platform に移行しましたが既存のモニタリング プラットフォームを使用していました。
しかし、通知システムがタイムクリティカルな問題に対して遅すぎることがわかりました。
どうしたらいいでしょうか?
- A.モニタリング プラットフォーム全体を Stackdriver に置き換えます。
- B. Google Compute Engine インスタンスに Stackdriver エージェントをインストールします。
- C. Stackdriver を使用してログをキャプチャしてアラートを設定し、既存のプラットフォームに送信します。
- D. 一部のトラフィックを古いプラットフォームに移行し、2つのプラットフォームで同時にABテストを行ないます。
Correct Answer: B
Reference contents:
– Google Cloud Monitoring | Google Cloud
Question 3
MySQL データベースを Google Cloud Platfrom の Google Cloud SQL データベースに移行しようとしています。
この Google Cloud SQL インスタンスに接続する Google Compute Engine 仮想マシン インスタンスがあります。Google Cloud SQL にアクセスできるようにするために Google Compute Engine インスタンス IP をホワイトリストに登録したくありません。
どうすればよいでしょうか?
- A. Google Cloud SQL インスタンスのプライベート IP を有効にします。
- B. Google Cloud SQL にアクセスするプロジェクトをホワイトリストに登録し、ホワイトリストに登録されたプロジェクトにGoogle Compute Engine インスタンスを追加します。
- C. Google Cloud SQL に外部インスタンスからのデータベースへのアクセスを許可するロールを作成し、そのロールにGoogle Compute Engine インスタンスを割り当てます。
- D. 1つのプロジェクトにGoogle Cloud SQL インスタンスを作成する。別のプロジェクトにGoogle Compute Engine インスタンスを作成する。これら2つのプロジェクト間にVPNを作成し、Google Cloud SQL への内部アクセスを可能します。
Correct Answer: C → A
Reference contents:
– 外部アプリケーションから Cloud SQL に接続する | Google Cloud
– MySQL クライアントを Compute Engine から接続する | Cloud SQL for MySQL
Question 4
次の gcloud コマンドを使用して HTTP(s) Load Balancer をデプロイしました。
export NAME-load-balancer
# create network
gcloud compute networks create ${NAME}
# add instance
gcloud compute instances create ${NAME} -backend-instance-1 --subnet ${NAME} --no address
# create the instance group
gcloud compute instance-groups unmanaged create ${NAME} -i
gcloud compute instance-groups unmanaged set-named-ports ${NAME}-i --named-ports http:80 gcloud compute instance-groups unmanaged add-instances ${NAME}-i --instances ${NAME}-instance-1
# configure health checks
gcloud compute health-checks create http ${NAME}-http-hc --port 80
# create backend service
gcloud compute backend-services create ${NAME} -http-bes --health-checks ${NAME} -http-hc --protocol HTTP --port-name http --global
gcloud compute backend-services add-backend ${NAME} -http-bes --instance-group ${NAME} -i --balancing-mode RATE --max-rate 100000 --capacity-scaler 1.0 --global --instance-group-zone us-east1-d
# create urls maps and forwarding rule
gcloud compute url-maps create ${NAME}-http-urlmap --default-service ${NAME}-http-bes
gcloud compute target-http-proxies create ${NAME} -http-proxy --url-map ${NAME} -http-urlmap
gcloud compute forwarding-rules create ${NAME} -http-fw --global --ip-protocol ICP --target-http-proxy ${NAME} -http-proxy --ports 80Google Compute Engine 仮想マシンインスタンス上のポート 80へのヘルスチェックが失敗しており、インスタンスにトラフィックが送信されません。この問題を解決したいと思います。
どのコマンドを実行するべきでしょうか?
- A. gcloud compute instances add-access-config ${NAME}-backend-instance-1
- B. gcloud compute instances add-tags ${NAME}-backend-instance-1 –tags http-server
- C. gcloud compute firewall-rules create allow-lb –network load-balancer –allow tcp –source-ranges 130.211.0.0/22,35.191.0.0/16 –direction INGRESS
- D. gcloud compute firewall-rules create allow-lb –network load-balancer –allow tcp –destination-ranges 130.211.0.0/22,35.191.0.0/16 –direction EGRESS
Correct Answer: C
Reference contents:
– ネットワーキング用に VM を構成したユースケース | VPC | Google Cloud
– ヘルスチェックの作成 | Load Balancing
Question 5
Webサイトは Google Compute Engine で公開されています。
マーケティングチームは 3つの異なるウェブサイトデザイン間のコンバージョン率をテストしたいと考えています。
どのアプローチを使うべきでしょうか?
- A. Google App Engine でWebサイトを公開し、トラフィックの分割を使用します。
- B. WebサイトをGoogle App Engine に 3つの独立したサービスとして公開します。
- C. Google Cloud Functions で Web サイトを公開し、トラフィックの分割を使用します。
- D. Google Cloud Functions で Web サイトを 3つの独立した機能として公開します。
Correct Answer: A
Reference contents:
–トラフィックの分割 | Google Cloud
Question 6
ローカルのスクリプトとそのすべてのコンテンツをローカルのワークステーションからGoogle Compute Engine VM インスタンスへコピーする必要があります。
どのコマンドを使用するべきでしょうか?
- A. gsutil cp –project “my-gcp-project” -r ~/local-scripts/ gcp-instance-name:~/server-scripts/ –zone “us-east1-b”
- B. gsutil cp –project “my-gcp-project” -R ~/local-scripts/ gcp-instance-name:~/server-scripts/ –zone “us-east1-b”
- C. gcloud compute scp –project “my-gcp-project” –recurse ~/local-scripts/ gcp-instance-name:~/server-scripts/ –zone “us-east1-b”
- D. gcloud compute mv –project “my-gcp-project” –recurse ~/local-scripts/ gcp-instance-name:~/server-scripts/ –zone “us-east1-b”
Correct Answer: C
Reference contents:
– gcloud compute copy-files | Cloud SDK Documentation | Google Cloud
– gcloud compute scp | Cloud SDK Documentation
Question 7
Stackdriver Monitoring エージェントがインストールされた Google Compute Engine VM インスタンスにアプリケーションをデプロイします。
アプリケーションはインスタンス上のUNIX プロセスです。 UNIX プロセスが少なくとも 5分間実行されなかった場合にアラートを表示させます。メトリックまたはログを生成するようにアプリケーションを変更することはできません。
どのアラート条件で構成するべきでしょうか?
- A. 稼働時間チェック
- B. プロセスの状態
- C. 指標の不在
- D. 指標しきい値
Correct Answer: B
Reference contents:
– アラートの動作 | Cloud Monitoring | Google Cloud
– アラート ポリシーの種類 #指標しきい値条件 | Cloud Monitoring
Question 8
ANSI-SQL に準拠したデータベース内に 2つのテーブルがあり、同じ列を持つテーブルを 1つのテーブルに素早く結合して結果セットから重複した行を削除する必要があります。
どうすればよいでしょうか?
- A. SQL でJOIN クエリを使用してテーブルを結合します。
- B. テーブルを結合するには、入れ子になったWITH ステートメントを使用します。
- C. SQL でUNION クエリを使用してテーブルを結合します。
- D. SQL でUNION ALL 演算子を使用してテーブルを結合します。
Correct Answer: C
Reference contents:
– SQL: UNION ALL Operator
Question 9
本番にデプロイされたアプリケーションがあります。
新しいバージョンがデプロイされるとアプリケーションが実稼働中のユーザーからトラフィックを受信するまでいくつかの問題は発生しませんが影響を受けるユーザー数と影響の大きさを減らしたいと考えます。
どのデプロイ戦略を使用しますか?
- A. ブルー/グリーン(Blue/green)デプロイメント
- B. カナリア(Canary)デプロイメント
- C. ローリング(Rolling)デプロイメント
- D. 再作成(Recreate) デプロイメント
Correct Answer: A → B
Reference contents:
– Six Strategies for Application Deployment – The New Stack
Question 10
会社は人気のあるアプリケーションのユーザーを米国外に拡大したいと考えています。
この会社はアプリケーション用のデータベースの可用性 99.999% を確保したいと考えており、また、世界中のユーザーのために読み取り遅延を最小限にしたいと考えています。
どのアクションをおこなうべきでしょうか?(回答を 2つ選んでください)
- A. nam-asia-eur1 構成でマルチリージョンの Google Cloud Spannerインスタンスを作成します。
- B. nam3 構成でマルチリージョンの Google Cloud Spanner インスタンスを作成します。
- C. 少なくとも 3つの Google Cloud Spanner ノードを持つクラスタを作成する。
- D. 少なくとも 1つの Google Cloud Spanner ノードを持つクラスタを作成する。
- E. 少なくとも 1つのノードで別々のリージョンに最低 2つのGoogle Cloud Spanner インスタンスを作成する。
- F. Google Cloud Dataflow パイプラインを作成して異なるデータベース間でデータを複製します。
Correct Answer: B、F → A、C
Reference contents:
– インスタンス #マルチリージョン構成 | Cloud Spanner
– Cloud Spanner 以外のデータベースからのデータ インポート
Question 11
500 MB のファイル サイズ制限が適用された内部ファイル アップロード API を Google App Engine に移行します。
何をするべきでしょうか?
- A. FTP を使用してファイルをアップロードします。
- B. cPanel を使用してファイルをアップロードします。
- C. 署名付き URL を使用してファイルをアップロードします。
- D. API をマルチパートファイル アップロード API に変更します。
Correct Answer: C
Reference contents:
– Google Cloud Platform
Question 12
Google Kubernetes Engine(GKE)クラスタにアプリケーションをデプロイすることを計画しています。
アプリケーションは、/healthz で HTTP ベースのヘルスチェックを公開します。このヘルスチェックエンドポイントを使用してトラフィックをロードバランサーによって Pod にルーティングする必要があるかどうかを判断します。
どのコード スニペットを Pod 構成に含めるべできしょうか?
- A.
livenessProbe:
httpGet:
path: /healthez
port: 80 - B.
readinessProbe:
httpGet:
path: /healthez
port: 80 - C.
loadbalancerHealthCheck:
httpGet:
path: /healthez
port: 80 - D.
HealthCheck:
httpGet:
path: /healthez
port: 80
Correct Answer: B
GKE Ingress コントローラが readinessProbe をヘルスチェックとして使用するには Ingress 用の Pod が Ingress の作成時に存在する必要があります。レプリカのサイズが 0 に設定されている場合はデフォルトの稼働状態チェックが適用されます。
Reference contents:
– Kubernetes ベスト プラクティス 6 選
Question 13
同僚から次のコードを確認するように依頼されました。
目的は多数の小さな行を Google BigQuery テーブルに効率的に追加することです。
BigQuery service = BigQueryOptions.newBuilder().build().getService();
public void writeTo BigQuery(Collection<Map<String, String>> rows){
for(Map>String, String> row : row){
InsertAllRequest insertRequest = insertAllRequest.newBuilder(
"datasetId", "tableID",
InsertAllRequest.RowToInsert.of(row)).build():
service.insertAll(insertReQuest);
}
}どの改善を提案が必要でしょうか?
- A. 各リクエストに複数の行を含めます。
- B. 複数のスレッドを作成して挿入を並行して実行します。
- C. 各行を Google Cloud Storage オブジェクトに書き込み、Google BigQuery に読み込むを行います。
- D. 各行を Google Cloud Storage オブジェクトに並行して書き込み、Google BigQuery に読み込むを行います。
Correct Answer: B → A
Reference contents:
– BigQuery へのデータのストリーミング #ストリーミング挿入の例
Question 14
Google Kubernetes Engine(GKE)上でホストされている JPEG 画像サイズ変更 API を開発していただきます。
サービスの呼び出し元は同じGKE クラスタ内に存在し、クライアントがサービスの IP アドレスを取得できるようにしたいとします。
何をすべきでしょうか?
- A. GKE サービスを定義し、クライアントは Google Cloud DNS のA レコードの名前を使用してサービスのクラスタ IP アドレスを見つける必要があります。
- B. GKE サービスを定義し、クライアントはサービスに接続するための URL にあるサービス名を使用する必要があります。
- C. GKE エンドポイントを定義し、クライアントはクライアントコンテナ内の適切な環境変数からエンドポイント名を取得してください。
- D. GKE エンドポイントを定義し、クライアントは Google Cloud DNS からエンドポイント名を取得してください。
Correct Answer: C
Reference contents:
– サービス ディスカバリと DNS | Kubernetes Engine ドキュメント
Question 15
Google Cloud Build を使用して Google Cloud Source Repositories に保存されているアプリケーションのソースコードをビルドしてテストしています。
ビルド処理には Google Cloud Build 環境では利用できないビルドツールが必要です。
どうすればよいでしょうか?
- A. ビルド中にインターネットからバイナリをダウンロードする。
- B. カスタム Google Cloud Builder イメージを作成してビルド手順でそのイメージを参照します。
- C. バイナリを Google Cloud Source Repositories リポジトリに含め、ビルド スクリプトで参照します。
- D. Google Cloud Build 公開バグトラッカーに対して機能のリクエストを提出してバイナリを Google Cloud Build 環境に追加してもらうように依頼します。
Correct Answer: B
Reference contents:
– コミュニティ提供のビルダーとカスタム ビルダーの使用 #カスタム ビルダーの作成
Question 16
アプリケーションをGoogle Compute Engine 仮想マシン インスタンスにデプロイしています。
アプリケーションはログファイルをディスクに書き込むように設定されており、アプリケーションのコードを変更せずに Stackdriver Logging でログを表示したいとします。
どうすればよいでしょうか?
- A. Stackdriver Logging エージェントをインストールしてアプリケーション ログを送信するように設定します。
- B. Stackdriver Logging ライブラリを使用してアプリケーションから Stackdriver Logging に直接ログを記録します。
- C. インスタンスのメタデータにログ ファイルのフォルダ パスを指定してアプリケーション ログを送信するように構成します。
- D. アプリケーションのログが自動的に Stackdriver Logging に送信されるようにアプリケーションのログを/var/log に変更します。
Correct Answer: A
Question 17
使用しているサービスでは Google Cloud Storage から読み取った画像にテキストが追加されます。
繁忙期にはGoogle Cloud Storage へのリクエストが HTTP 429 のステータス コード「Too Many Requests」で失敗します。
このエラーはどのように対処すればよいでしょうか?
- A. オブジェクトにキャッシュ コントロールヘッダを追加します。
- B. Google Cloud コンソールから割り当ての増加を要求します。
- C. 切り捨て指数バックオフ戦略を使用してリクエストを再試行します。
- D. Google Cloud Storage バケットのストレージクラスを Multi-regional に変更します。
Correct Answer: C
Reference contents:
– Usage limits | Gmail API | Google Developers
– HTTP status and error codes for JSON | Cloud Storage
Question 18
Android とiOS のアプリで使用される API を構築しています。
その API は「HTTPをサポートすること」「帯域幅のコストを最小限に抑えること」「モバイルアプリと簡単に統合すること」が条件です
どの API アーキテクチャを使うべきでしょうか?
- A. RESTful APIs
- B. MQTT for APIs
- C. gRPC-based APIs
- D. SOAP-based APIs
Correct Answer: A
Reference contents:
– How to Build a RESTful API for Your Mobile App?
– API 設計: gRPC、OpenAPI、REST の概要と、それらを使用するタイミングを理解する
Question 19
あなたのアプリケーションはユーザーから入力を受け取り、それをユーザーの連絡先に公開します。
この入力は Google Cloud Spanner テーブルに保存されます。このアプリケーションはレイテンシーの影響を受けやすく、一貫性の影響を受けにくくなっています。
このアプリケーションでは Google Cloud Spanner からの読み取りをどのように行うべきでしょうか?
- A. 読み取り専用トランザクションを実行します。
- B. 単一読み取りメソッドを使用してステイル読み取りを実行します。
- C. 単一読み取りメソッドを使用して強力な読み取りを実行します。
- D. 読み取り/書き込みトランザクションを使用してステイル読み取りを実行します。
Correct Answer: D → B
Reference contents:
– ゲーム データベースとして Cloud Spanner を使用する場合のベスト プラクティス | Google Cloud
– 読み取り | Cloud Spanner
Question 20
アプリケーションは Google Kubernetes Engine(GKE)クラスタにデプロイされています。
アプリケーションの新しいバージョンがリリースされると CI/CD ツールは spec.template.spec.containers[0].image の値を更新して新しいアプリケーション バージョンのDocker イメージを参照します。Deployment オブジェクトが変更を適用するとき、新しいバージョンのレプリカを少なくとも1つデプロイし、新しいレプリカが健全になるまで以前のレプリカを維持したいと思います。
次の Kubernetes Deployment オブジェクトにどの変更を加えればよいでしょうか?
apiVersion: apps/v1
kind: Deploment
metadata:
name: ecommerce-frontend-deployment
spec:
replicas: 3
selector:
matchLabels:
app: ecommerce-frontend
spec:
containers:
- name: ecommerce-frontend-webapp
image:ecommerce-frontend-webapp:1.7.9
ports:
- containerPort: 80- A. maxSurge=0 maxUnavailable=1 に設定して Deployment strategy を Recreate に設定します。
- B. maxSurge=1 maxUnavailable=0 に設定して Deployment strategy を Recreate に設定します。
- C. maxSurge=1 maxUnavailable=0 に設定して Deployment strategy を rollingUpdate に設定します。
- D. maxSurge=0 maxUnavailable=1 に設定して Deployment strategy を rollingUpdate に設定します。
Correct Answer: A → C
Reference contents:
– 標準クラスタのアップグレード | Kubernetes Engine ドキュメント | Google Cloud
– ローリング アップデートの実施 | Kubernetes Engine ドキュメント | Google Cloud
Question 21
簡単なHTML アプリケーションをインターネット上で公開する予定です。
このサイトではアプリケーションのFAQに関する情報を保持しています。このアプリケーションは静的なもので、画像、HTML、CSS、Javascript が含まれています。
このアプリケーションをできるだけ少ない手順でインターネット上で利用できるようにしたいと考えています。
どうすればいいのでしょうか?
- A. Google Cloud Storage にアプリケーションをアップロードします。
- B. Google App Engine 環境にアプリケーションをアップロードします。
- C. Apache Web サーバーがインストールされた Google Compute Engine インスタンスを作成します。アプリケーションをホストするために Apache Web サーバーを設定します。
- D. 最初にアプリケーションをコンテナ化します。このコンテナを Google Kubernetes Engine(GKE)にデプロイし、アプリケーションをホストする GKE ポッドに外部 IP アドレスを割り当てます。
Correct Answer: A
Reference contents:
– 静的ウェブサイトのホスティング | Cloud Storage | Google Cloud
Question 22
会社はGoogle App EngineStandard環境に新しいAPIをデプロイしました。
テスト中、API が期待通りに動作しません。アプリケーションを再デプロイせずにアプリケーション コード内の問題を診断するために、アプリケーションを長期にわたって監視する必要があります。
どのツールを使うべきでしょうか?
- A. Stackdriver Trace
- B. Stackdriver Monitoring
- C. Stackdriver デバッグ スナップショット
- D. Stackdriver デバッグ ログポイント
Correct Answer: B → D
Reference contents:
– GCP Stackdriver Tutorial : Debug Snapshots, Traces, Logging and Logpoints
Question 23
Stackdriver Logging エージェントを使用して Google Compute Engine 仮想マシン インスタンスから Stackdriver にアプリケーションのログ ファイルを送信したいと考えています。
Stackdriver Logging エージェント をインストールした後、最初に何をすればいいでしょうか?
- A. プロジェクトで Error Reporting API を有効にします。
- B. インスタンスにすべての Google Cloud API へのフルアクセスを付与します。
- C. アプリケーションのログファイルをカスタムソースとして設定します。
- D. アプリケーションのログ エントリに一致するフィルタを持つ Stackdriver ログのエクスポート シンクを作成します。
Correct Answer: B → C
Reference contents:
– エージェントの構成 #追加入力からログをストリーミングする | Cloud Logging
Question 24
会社には数百人の従業員に分析情報を提供する Google BigQuery データマートがあります。
ユーザーは重要なワークロードを中断することなくジョブを実行したいと考えています。このユーザーはジョブの実行にかかる時間を気にしていません。会社のコストとエンジニアの労力を最小限に抑え、この要求を満たしたいと考えています。
何をすべきでしょうか?
- A. ジョブをバッチ ジョブとして実行するようにユーザーに依頼します。
- B. ユーザーがジョブを実行するために別のプロジェクトを作成します。
- C. 既存のプロジェクトに job.user の役割としてユーザーを追加します。
- D. 重要なワークロードが実行されていないときにユーザーがジョブを実行できるようにします。
Correct Answer: B
Reference contents:
– インタラクティブ クエリとバッチクエリのジョブの実行 #バッチクエリの実行 | BigQuery
Question 25
開発時間を最小限に抑えつつ、本番でのサービス低下をオンコール担当エンジニアに通知したいと考えています。
何をすべきでしょうか?
- A. Google Cloud Functions を使用してリソースをキャプチャし、アラートを生成します。
- B. Google Cloud Pub/Sub を使用してリソースをキャプチャし、アラートを生成します。
- C. Stackdriver Error Reporting を使用してエラーをキャプチャし、アラートを生成します。
- D. Stackdriver Monitoring を使用してリソースをキャプチャし、アラートを生成します。
Correct Answer: A → D
Question 26
XMLHttpRequest を使ってサードパーティの API とコンテンツの通信を行うユーザーインターフェイス(UI)を備えた単一ページのWebアプリケーションを作成しています。
API の結果によってUI に表示されるデータは同じWebページに表示される他のデータよりも重要度が低いため、リクエストによってはAPI のデータがUI に表示されないことも許容されます。ただし、API への呼び出しによってUI の他の部分のレンダリングが遅れることがあってはなりません。API のレスポンスがエラーやタイムアウトになった場合でもアプリケーションのパフォーマンスを向上させたいと考えています。
どうすればいいのでしょうか?
- A. API へのリクエストの非同期オプションを false に設定し、タイムアウトやエラーが発生したときにAPI の結果を表示するウィジェットを省略します。
- B. API へのリクエストの非同期オプションを true に設定し、タイムアウトやエラーが発生したときにAPI の結果を表示するウィジェットを省略します。
- C. API 呼び出しからのタイムアウトやエラーの例外をキャッチし、API レスポンスが成功するまで指数関数的バックオフで試行を続けます。
- D. API 呼び出しからのタイムアウトまたはエラー例外をキャッチし、UI ウィジェットにエラー応答を表示します。
Correct Answer: A → B
Question 27
任意のユーザーの Google ドライブ にファイルを書き込む Google App Engine アプリケーションを作成しています。
このアプリケーションは Google ドライブ API に対してどのように認証を行うべきでしょうか?
- A. https://www.googleapis.com/auth/drive.file スコープを使って各ユーザーのアクセストークンを取得するOAuth クライアント ID を使用します。
- B. ドメイン全体の権限を委譲された OAuth クライアント ID を使用します。
- C. Google App Engine サービスアカウントと https://www.googleapis.com/auth/drive.file スコープを使用して、署名付き JWT を生成します。
- D. ドメイン全体の権限を委譲された Google App Engine サービス アカウントを使用します。
Correct Answer: B → A
Reference contents:
– Authenticate your users | Google Drive API | Google Developers
Question 28
Google Kubernetes Engine(GKE)クラスタを作成して次のコマンドを実行します。
gcloud container clusters create large-cluster--num-bides 200実行コマンドは失敗し、エラー表示されました。
insufficient regional quota to satisfy request: resource "CPUS": request requires '200.0' and is short '176..0'. project has quota of '24.0' with '24.0' available.問題を解決するにはどうすればいいのでしょうか?
- A. Google Cloud Consoleで GKE 割り当ての追加をリクエストします。
- B. Google Cloud Consoleで Google Compute Engine 割り当ての追加をリクエストします。
- C. サポートケースを開き、GKE 割り当ての追加をリクエストします。
- D. クラスタ内のサービスをデカップリングし、より少ないコア数で機能するように新しいクラスタを書き換えます。
Correct Answer: A → B
Reference contents:
– 割り当てと上限 #クラスタあたりの上限 | Kubernetes Engine ドキュメント
Question 29
タイムスタンプ、口座番号(文字列)、取引額(数字)の3つの列を含むログファイルを解析しています。
固有の口座番号ごとにすべての取引金額の合計を効率的に計算したいと考えています。
どのデータ構造を使うべきでしょうか?
- A. リンクリスト
- B. ハッシュテーブル
- C. 二次元配列
- D. カンマで区切られた文字列
Correct Answer: B
Question 30
会社には従業員の旅費と経費に関する情報を保持する「Master」という名前のGoogle BigQuery データセットがあります。
この情報は従業員部門別に整理されています。 つまり、従業員は自分の部門の情報のみを表示できる必要があります。セキュリティフレームワークを適用して最小限の手順でこの要件を実施します。
何をするべきでしょうか?
- A. 各部門ごとに個別のデータセットを作成します。特定の部門の特定のデータセットからレコードを選択するために適切な WHERE ステートメントを持つビューを作成します。このビューにMaster データセットのレコードにアクセスします。この部門固有のデータセットに対する権限を従業員に付与します。
- B. 部門ごとに個別のデータセットを作成する。各部門のデータパイプラインを作成して、Master データセットから部門の特定のデータセットに適切な情報をコピーします。 この部門固有のデータセットに対する権限を従業員に付与します。
- C. Master データセットという名前のデータセットを作成します。Master データセットの部門ごとに個別のビューを作成します。 従業員が自分の部門の特定のビューにアクセスできるようにします。
- D. Master データセットという名前のデータセットを作成する。Master データセットの部門ごとに個別のテーブルを作成します。 従業員が自分の部門の特定のテーブルにアクセスできるようにします。
Correct Answer: B → C
Question 31
実稼働中のアプリケーションがあります。
マネージド インスタンス グループよって制御される Google Compute Engine VM マシンインスタンスにデプロイされます。トラフィックは HTTP (s) ロードバランサーを介してインスタンスにルーティングされます。ユーザーはアプリケーションにアクセスできません。アプリケーションが使用できない場合に警告する監視手法を実装する必要があります。
どの監視手法を良いでしょうか?
- A. スモークテスト
- B. Stackdriver の稼働時間チェック
- C. Google Cloud Load Balancing のヘルスチェック
- D. マネージド インスタンス グループ のヘルスチェック
Correct Answer: B
Reference contents:
– Stackdriver Monitoring Automation Part 3: Uptime Checks | by Charles | Google Cloud – Community
Question 32
サーバーアプリケーションの負荷テストを行っています。
最初の 30秒間にこれまで非アクティブだった Google Cloud Storage バケットが毎秒 2,000の書き込みリクエストと毎秒 7,500の読み取りリクエストを処理していることがわかりました。需要が高まるにつれて、アプリケーションは Google Cloud Storage JSON API から断続的に 5xx および 429 HTTP レスポンスを受信するようになりました。Google Cloud Storage API からの失敗したレスポンスを減らしたいと考えています。
何をするべきでしょうか?
- A. アップロードを多数のファイルをストレージバケットに分散します。
- B. Google Cloud Storage とのインターフェースには、JSON API の代わりにXML API を使用します。
- C. HTTP レスポンスコードを、アプリケーションからアップロードを呼び出しているクライアントに返します。
- D. アプリケーションクライアントからのアップロードレートを制限して、休止バケットのピークリクエストレートに徐々に到達するようにします。
Correct Answer: A → D
Reference contents:
– リクエスト レートとアクセス配信のガイドライン #リクエスト レートを徐々に増やす | Cloud Storage | Google Cloud
Question 33
アプリケーションはマネージド インスタンス グループによって制御されます。
マネージド インスタンス グループ内のすべてのインスタンス間で大きな読み取り専用データセットを共有を行いたいと考えています。そのために、各インスタンスを迅速に起動し、ファイルシステムを介して非常に低いレイテンシでデータセットにアクセスできるようにする必要があり、ソリューションの総コストを最小限に抑える必要もあります。
何をするべきでしょうか?
- A. データを Google Cloud Storage のバケットに移動し、Google Cloud Storage FUSE を使用してバケットをファイルシステムにマウントします。
- B. データを Google Cloud Storage のバケットに移動し、起動スクリプトを介してデータをインスタンスのブートディスクにコピーします。
- C. データを Google Compute Engine の永続ディスクに移動し、読み取り専用モードでディスクを複数のGoogle Compute Engine VM マシンインスタンスに接続します。
- D. データを Google Compute Engine の永続ディスクに移動し、スナップショットを取得し、スナップショットから複数のディスクを作成し、各ディスクを独自のインスタンスに接続します。
Correct Answer: C
Reference contents:
– ディスクの作成とアタッチ | Compute Engine ドキュメント
Question 34
同じ Virtual Private Cloud(VPC)内の複数のクライアントによって呼び出す必要があるGoogle Compute Engine VM インスタンスでホストされる HTTP API を開発しています。クライアントがサービスのIPアドレスを取得できるようにします。
何をするべきでしょうか?
- A. 静的外部 IP アドレスを予約して HTTP (S) ロードバランサ の転送ルールに割り当てます。 クライアントはこのIP アドレスを使用してサービスに接続する必要があります。
- B. 静的外部 IP アドレスを予約して HTTP (S) ロードバランサ の転送ルールに割り当てます。 次に、Google Cloud DNS でA レコードを定義します。 クライアントは A レコードの名前を使用してサービスに接続する必要があります。
- C. URL https://[INSTANCE_NAME].[ZONE].c. [PROJECT_ID].internal/ でインスタンス名に接続することにより、クライアントが Google Compute Engine の内部 DNS を使用するようにします。
- D. URL https://[API_NAME]/[API_VERSION]/ でインスタンス名に接続することにより、クライアントが Google Compute Engine の内部 DNS を使用するようにします。
Correct Answer: D → C
Question 35
アプリケーションは Stackdriver にログを記録しています。
すべての /api/alpha/* エンドポイントのすべてのリクエストの数を取得したいとします。
どうすればいいのでしょうか?
- A. パス:/api/alpha/ にStackdriver のカウンターメトリックを追加します。
- B. エンドポイント:/api/alpha/* のためのStackdriver のカウンターメトリックを追加します。
- C. ログをGoogle Cloud Storage にエクスポートし、/api/alpha に一致する行をカウントします。
- D. Google Cloud Pub/Sub にログをエクスポートし、/api/alpha に一致する行をカウントします。
Correct Answer: C → A
Reference contents:
– カウンタ指標の作成 | Cloud Logging
Question 36
モノリシック アプリケーションをマイクロサービス モデルに従うように再設計したいとします。
この変更がビジネスに与える影響を最小限に抑えながら効率的にこれを達成したいと考えています。
どのアプローチを取るべきでしょうか?
- A. アプリケーションを Google Compute Engine にデプロイし、オートスケーリングをオンにします。
- B. アプリケーションの機能を段階的に適切なマイクロサービスに置き換えます。
- C. 一度の作業で適切なマイクロサービスでモノリシック アプリケーションをリファクタリングし、デプロイします。
- D. モノリスとは別に適切なマイクロサービスで新しいアプリケーションを構築し、それが完成したら置き換えます。
Correct Answer: C → B
Reference contents:
– モノリシック アプリケーションを Google Kubernetes Engine のマイクロサービスに移行する | Google Cloud
Question 37
既存のアプリケーションはユーザーの状態情報を単一の MySQL データベースに保持しています。
この状態情報は非常にユーザー固有のものであり、ユーザーがアプリケーションをどのくらいの期間使用しているかに大きく依存しています。MySQL データベースは様々なユーザーのためにスキーマを維持および拡張するという課題を引き起こしています。
どのストレージ オプションを選択すべきでしょうか?
- A. Google Cloud SQL
- B. Google Cloud Storage
- C. Google Cloud Spanner
- D. Google Cloud Datastore/Firestore
Correct Answer: A → D
Reference contents:
– MySQL から Cloud SQL への移行 | Solutions | Google Cloud
– Datastore の概要 #最適な用途 | Cloud Datastore ドキュメント
Question 38
新しいAPI を構築しています。
画像を保存するコストを最小限に抑え、画像を提供する際の待ち時間を短縮したいと考えています。
どのアーキテクチャを使用しますか?
- A. Google Cloud Storage にバックアップされた Google App Engine。
- B. Persistent Disk にバックアップされた Google Compute Engine。
- C. Google Cloud Filestore にバックアップされた Transfer Appliance。
- D. Google Cloud Storage にバックアップされた Google Cloud Content Delivery Network(CDN)。
Correct Answer: B → D
Question 39
会社の開発チームはプロジェクトで Google Cloud Build を使用してDocker イメージをビルドし、Google Cloud Container Registry にプッシュしたいと考えています。
運用チームはすべてのDocker イメージを運用チームが管理する安全に管理された中央のDocker レジストリに公開することを要求しています。
何をすべきでしょうか?
- A. Google Cloud Container Registry を使用して各開発チームのプロジェクトにレジストリを作成します。 Docker イメージをプロジェクトのレジストリにプッシュするように Google Cloud Build のビルドを構成します。運用チームに各開発チームのレジストリへのアクセスを許可します。
- B. Google Cloud Container Registry が構成されている運用チーム用に別のプロジェクトを作成します。各開発者チームのプロジェクトの Google Cloud Build サービス アカウントに適切な権限を割り当てて、運用チームのレジストリへのアクセスを許可します。
- C.Google Cloud Container Registry が構成されている運用チーム用に別のプロジェクトを作成します。開発チームごとにサービス アカウントを作成し、適切な権限を割り当て、運用チームのレジストリへのアクセスを許可します。サービス アカウント キーファイルをソースコード リポジトリに保存し、使用して運用チームのレジストリに対して認証します。
- D. Google Compute Engine 仮想マシンインスタンスにオープンソースのDocker レジストリがデプロイされている運用チーム用に別のプロジェクトを作成します。開発チームごとにユーザー名とパスワードを作成します。ユーザー名とパスワードをソースコードリポジトリに保存し、使用して運用チームのDocker レジストリに対して認証します。
Correct Answer: A → B
Reference contents:
– Google Cloud Container Registry | Google Cloud
Question 40
Google Kubernetes Engine (GKE) クラスタにアプリケーションをデプロイすることを計画しています。
アプリケーションは水平スケーリングが可能でアプリケーションの各インスタンスには安定したネットワーク ID と独自の永続ディスクが必要です。
どの GKE オブジェクトを使用するべできでしょうか?
- A. Deployment
- B. StatefulSet
- C. ReplicaSet
- D. ReplicaController
Correct Answer: B → C
Reference contents:
– Chapter 10. StatefulSets: deploying replicated stateful applications · Kubernetes in Action
Question 41
Google Cloud Buildを使用してDocker イメージを構築しています。
ユニットを実行して統合テストを実行するにはビルドを変更する必要があります。障害が発生した場合はビルドが失敗した段階をビルド履歴を明確に表示します。
何をするべきでしょうか?
- A. Dockerfile に RUN コマンドを追加して単体テストと統合テストを実行します。
- B. 単体テストと統合テストをコンパイルする単一のビルドステップで Google Cloud Build のビルド構成ファイルを作成します。
- C. Google Cloud Build のビルド構成ファイルを作成します。このファイルは、単体テストと統合テスト用に個別のクラウドビルドパイプラインを生成します。
- D. 単体テストと統合テストをコンパイルして実行するための個別の Google Cloud Build の手順を使用して Google Cloud Build のビルド構成ファイルを作成します。
Correct Answer: D
Question 42
コードはプロジェクト AのGoogle Cloud Functions 上で実行されています。
プロジェクト B が所有する Google Cloud Storage バケットにオブジェクトを書き込むことになっていますが、書き込み呼び出しが 「403 Forbidden」というエラーで失敗しています。
この問題を修正するにはどうすればよいでしょうか?
- A. ユーザーアカウントに Google Cloud Storage バケットの roles/storage.objectCreator の役割を付与します。
- B. ユーザーアカウントに service-PROJECTA@gcf-admin-robot.iam.gserviceaccount.com サービス アカウントの roles/iam.serviceAccountUser の役割を付与します。
- C. service-PROJECTA@gcf-admin-robot.iam.gserviceaccount.com サービス アカウントに Google Cloud Storage バケット用の roles/storage.objectCreator の役割を付与します。
- D. プロジェクト B で Google Cloud Storage API を有効にします。
Correct Answer: B →C
Reference contents:
– アクセス制御 | Cloud Functions ドキュメント
Question 43
この問題については HipLocal のケーススタディを参照してください。
HipLocal の .net ベースの認証サービスが断続的な負荷で失敗します。
どうしたらいいでしょうか?
- A. Google App Engine でオートスケーリングを使用します。
- B. Google Cloud Functions を使用してオートスケーリングを使用します。
- C. サービスに Google Compute Engine クラスタを使用します。
- D. サービス専用の Google Compute Engine 仮想マシンインスタンスを使用します。
Correct Answer: D → A
Reference contents:
– Autoscaling an Instance Group with Custom Cloud Monitoring Metrics
Question 44
この問題については HipLocal のケーススタディを参照してください。
HipLocal の API は時々障害を起こしますが、パターンを特定できていません。トラブルシューティングのためにいくつかの指標を収集したいと考えています。
何をすべきでしょうか?
- A. すべてのVM のスナップショットを頻繁に作成します。
- B. Google Stackdriver Logging エージェントをVMにインストールします。
- C. VM にGoogle Stackdriver Monitoring エージェントをインストールします。
- D. Google Stackdriver Trace を使用してパフォーマンスのボトルネックを探します。
Correct Answer: C
Question 45
この問題については HipLocal のケーススタディを参照してください。
HipLocal は永続ディスクに保存されたデータをクエリするために Google Cloud Interconnect を使用して Hadoop インフラストラクチャをGCPに接続しています。
どの IP 戦略を使用すべきですか?
- A. 手動でサブネットを作成します。
- B. 自動モードのサブネットを作成します。
- C. 複数のピアリング VPC を作成します。
- D. NAT の単一インスタンスをプロビジョニングします。
Correct Answer: A
Question 46
この問題については HipLocal のケーススタディを参照してください。
HipLocal は使って内部アプリへのアクセスを可能するのはどのサービスでしょうか?
- A. Google Cloud VPN
- B. Google Cloud Armor
- C. Virtual Private Cloud
- D. Google Cloud Identity-Aware Proxy
Correct Answer: D → A
Reference contents:
– オンプレミス アプリの IAP の概要 | Identity-Aware Proxy | Google Cloud
Question 47
この問題については HipLocal のケーススタディを参照してください。
HipLocal はオンコール担当エンジニアの数を減らし、手動によるスケーリングをなくしたいと考えています。
どのサービスを選ぶべきでしょうか?(回答を 2つ選んでください)
- A. Google App Engine を利用します。
- B. サーバーレスの Google Cloud Functions を使用します。
- C. Knative を使用してサーバーレス アプリケーションを構築およびデプロイします。
- D. 自動化されたデプロイメントのために Google Kubernetes Engine を使用します。
- E. 大規模な Google Compute Engine クラスタを使用してデプロイします。
Correct Answer: B、C → A、B
Question 48
この問題については HipLocal のケーススタディを参照してください。
HipLocal はビジネス要件を満たすためにどのようにアプリケーションの状態を保存すべきでしょうか?
- A. ローカル SSDを使用して状態を保存します。
- B. MySQL の前にmemcache 層を設置します。
- C. ステートストレージを Google Cloud Spanner に移行します。
- D. MySQL インスタンスを Google Cloud SQLに置き換えます。
Correct Answer: B → C
Question 49
この問題については HipLocal のケーススタディを参照してください。
HipLocal はどのサービスを公開 API に使用するべきでしょうか?
- A. Google Cloud Armor
- B. Google Cloud Functions
- C. Google Cloud Endpoints
- D. Shielded Virtual Machines
Correct Answer: C
Question 50
この問題については HipLocal のケーススタディを参照してください。
HipLocal はビジネスと技術の要件を満たしつつ、MySQL 導入の耐障害性を向上させたいと考えています。
どの構成を選択すべきでしょうか?
- A. 現在の Google Compute Engine 上のシングルインスタンスのMySQL と Google Compute Engine の複数の読み取り専用 MySQL サーバーを使用します。
- B. Google Compute Engine で現在の単一のインスタンス MySQL を使用して外部マスター構成で Google Cloud SQL にデータを複製します。
- C. 現在の単一の MySQL インスタンスを Google Cloud SQL で置き換え、高可用性を構成します。
- D. 現在の単一の MySQL インスタンスを Google Cloud SQL に置き換えると Google からさらなる構成なしに冗長性を提供されます。
Correct Answer: B → C
Question 51
アプリケーションは複数の Google Kubernetes Engine クラスタで実行されています。
各クラスタのデプロイメントによって管理されており、Deployment は各クラスタにPod の複数のレプリカを作成しています。すべてのクラスタにある Deployment 内のすべてのレプリカの標準出力に送信されたログを表示したいと考えています。
どのコマンドを使用するべきでしょうか?
- A. kubectl logs [PARAM]
- B. gcloud logging read [PARAM]
- C. kubectl exec “”it [PARAM] journalctl
- D. gcloud compute ssh [PARAM] “”-command= “sudo journalctl”
Correct Answer: D → A
Reference contents:
– Config Sync ログの表示
Question 52
Google Cloud Build を使用して Google Cloud Source Repositories リポジトリへの各ソースコードのコミットに新しい Docker イメージを作成しています。アプリケーションはマスターブランチへのコミットごとに構築されており、マスターブランチへの特定のコミットを自動化された方法でリリースしたいと考えています。
どうすればよいでしょうか?
- A. 新しいリリースのために手動でビルドをトリガーします。
- B. Git タグのパターンにビルド トリガーを作成します。新しいリリースのために Git タグの規約を使用します。
- C. Git ブランチ名のパターンでビルドトリガーを作成する。新しいリリースでは、Git ブランチの命名規則を使用します。
- D. 2つ目の Google Cloud Source Repositories リポジトリに 2つ目の Google Cloud Build トリガーでソースコードをコミットします。このリポジトリは新しいリリースにのみ使用します。
Correct Answer: C → B
Question 53
MySQL から Google Cloud Bigtable に移行するテーブル構成を設計しています。MySQL のテーブルは次になります。
AccountActivity
(
Account_id int,
Event_timestamp datetime,
Transaction_type string,
Amount numeric (18,4)
) primary key (Account_id, Event_timestamp)このテーブルのGoogle Cloud Bigtable の行キーはどのように設計すればよいのでしょうか?
- A. Account_id をキーに設定します。
- B. Account_id_Event_timestamp をキーに設定します。
- C. Event_timestamp_Account_id をキーとして設定します。
- D. Event_timestamp をキーに設定します。
Correct Answer: C → B
Reference contents:
– スキーマの設計 | Cloud Bigtable ドキュメント
Question 54
Google Compute Engine にデプロイされたアプリケーションのメモリ使用量を表示したいとします。
何をするべきでしょうか?
- A. Stackdriver Client Libraries をインストールします。
- B. Stackdriver Monitoring エージェントをインストールします。
- C. Stackdriver Metrics Explorer を使用します。
- D. Google Cloud Console を使用します。
Correct Answer: C → B
Reference contents:
– Google Cloud Platform: how to monitor memory usage of VM instances
– Agent metrics | Cloud Monitoring
Question 55
Google BigQuery API を使用して数分ごとに Google BigQuery で数百のクエリを実行する分析アプリケーションがあります。
これらのクエリの実行にかかる時間を調べたいと思います。
何をするべきか?
- A. Stackdriver Monitoring でスロットの使用状況を確認します。
- B. Stackdriver Trace を使用して API の実行時間をプロットします。
- C. Stackdriver Trace を使用してクエリの実行時間をプロットします。
- D. Stackdriver Monitoring を使用してクエリの実行時間をプロットします。
Correct Answer: D
Reference contents:
– Google Cloud metrics #bigquery | Cloud Monitoring
Question 56
Google Cloud Spanner の顧客データベースのスキーマを設計しています。
顧客テーブルに電話番号の配列フィールドを格納し、ユーザーが電話番号で顧客を検索できるようにしたいと考えています。
このスキーマをどのように設計すべきでしょうか。
- A. Customers という名前のテーブルを作成します。顧客の電話番号を保持するArray フィールドをテーブルに追加します。
- B. Customers という名前のテーブルを作成します。Phones という名前のテーブルを作成します。Phones というテーブルにCustomerId フィールドを追加して、電話番号からCustomerIdを見つけます。
- C. Customers という名前のテーブルを作成します。顧客の電話番号を保持するテーブルにArray フィールドを追加します。Array フィールドにセカンダリインデックスを作成します。
- D. Customers という名前のテーブルを親テーブルとして作成します。Phones という名前のテーブルを作成し、このテーブルをCustomer テーブルにインターリーブします。Phonesというテーブルの電話番号フィールドにインデックスを作成します。
Correct Answer: C → D
Reference contents:
– スキーマとデータモデル #インターリーブされたテーブルの階層の作成 | Cloud Spanner
Question 57
Google App Engine に 1つのWebサイトを公開し、URL http://www.altostrat.com でアクセスできるようにする必要があります。
どうすればいいのでしょうか?
- A. Google Search Console (Webmaster Central) でドメインの所有権を確認します。DNS の CNAME レコードを作成して Google App Engine のカノニカル名 ghs.googlehosted.com を指すようにします。
- B. Google Search Console (Webmaster Central) でドメインの所有権を確認します。単一のグローバル Google App Engine IP アドレスを指す A レコードを定義します。
- C. dispatch.yaml でマッピングを定義し、ドメイン www.altostrat.com を Google App Engine サービスに指定します。DNS の CNAME レコードを作成して Google App Engine のカノニカル名 ghs.googlehosted.com を指定します。
- D. dispatch.yaml でマッピングを定義し、ドメイン www.altostrat.com を Google App Engine サービスに指定します。単一のグローバル Google App Engine IP アドレスを指す A レコードを定義します。
Correct Answer: A
Reference contents:
– カスタム ドメインのマッピング | App Engine flexible environment for .NET docs | Google Cloud
Question 58
継承した Google App Engine でアプリケーションを実行しています。
アプリケーションが安全でないバイナリを使用しているか、XSS 攻撃に対して脆弱であるかを調べたいと考えています。
どのサービスを使うべきでしょうか?
- A. Google Cloud Amor
- B. Stackdriver Debugger
- C. Google Cloud Security Scanner
- D. Stackdriver Error Reporting
Correct Answer: C
Reference contents:
– Google Cloud Security Command Center | Google Cloud
Question 59
ソーシャルメディアのアプリケーションを開発しています。
ユーザーが画像をアップロードできる機能を追加することを計画しています。画像のサイズは 2 MB ~ 1 GBです。この機能のためのインフラ運用のオーバーヘッドを最小限にしたいと考えています。
どうすればいいでしょうか?
- A. 画像を直接受け付けるようにアプリケーションを変更し、他のユーザー情報を保存するデータベースに画像を保存します。
- B. Google Cloud Storage 用の署名付き URL を作成するようにアプリケーションを変更します。これらの署名付き URLをクライアント アプリケーションに転送して Google Cloud Storage に画像をアップロードします。
- C. ユーザー画像を受け入れるようにGCP 上のWebサーバーを設定し、アップロードされたファイルを保持するファイルストアを作成します。ファイルストアから画像を取得するようにアプリケーションを変更します。
- D. Google Cloud Storage にユーザーごとに別のバケットを作成します。各バケットへの書き込みアクセスを許可するために別のサービスアカウントを割り当てます。ユーザー情報に基づいてサービスアカウントの資格情報をクライアントアプリケーションに転送します。アプリケーションはこのサービスアカウントを使用して Google Cloud Storage に画像をアップロードします。
Correct Answer: B
Reference contents:
– 署名付き URL を活用して Cloud Storage に画像ファイルを直接アップロードするアーキテクチャを設計する
Question 60
アプリケーションはカスタムマシン イメージとして構築されます。
マシンイメージの複数の固有のデプロイメントがあり、 各デプロイメントは独自のテンプレートを持つ個別のマネージド インスタンス グループです。 デプロイメントごとに固有の構成値のセットが必要です。 これらの一意の値を各デプロイメントに提供する必要がありますがすべてのデプロイメントで同じカスタムマシン イメージを使用します。 Google Compute Engine のすぐに使える機能を使用したいと考えています。
何をするべきかでしょうか?
- A. 永続ディスクに固有の構成値を配置します。
- B. Google Cloud Bigtable テーブルに固有の構成値を配置します。
- C. インスタンス テンプレートの起動スクリプトに固有の構成値を配置します。
- D. インスタンス テンプレートのインスタンス メタデータに固有の構成値を配置します。
Correct Answer: A → D
Reference contents:
– インスタンス グループ | Compute Engine Documentation | Google Cloud
Question 61
使用しているアプリケーションはローカルでテストした場合は正常に動作しますが Google App Engine standard 環境にデプロイした場合は動作が著しく遅くなります。
この問題を診断したいとします。
どうすればよいでしょうか?
- A. アプリケーションがローカルでより高速に動作することを示すチケットを GCP サポートに提出します。
- B. Stackdriver Debugger Snapshots を使用してアプリケーションのポイント イン タイム実行を確認します。
- C. Google Stackdriver トレースを使用してアプリケーション内のどの機能がより高いレイテンシを持つかを判断します。
- D. アプリケーションにロギング コマンドを追加し、Google Stackdriver Logging を使用して遅延の問題が発生している場所を確認します。
Correct Answer: D → C
Question 62
Google App Engine でアプリケーションを実行しています。
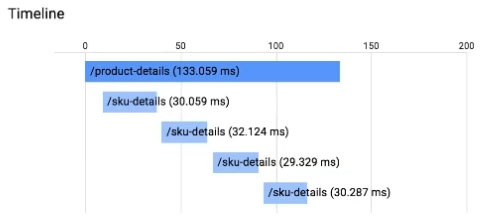
このアプリケーションは Stackdriver Trace で計測されています。/product-details リクエストは 以下のように /sku-details にある 4つの既知の一意の製品に関する詳細を報告します。リクエストが完了するまでの時間を短縮したいと考えています。
どうすればいいでしょうか?
- A. インスタンスクラスのサイズを大きくします。
- B. 永続ディスクタイプのタイプをSSD に変更します。
- C. product-details を変更してリクエストを並行して実行します。
- D. sku-details 情報をデータベースに保存してWebサービスの呼び出しをデータベース クエリに置き換えます。
Correct Answer: C
Question 63
会社では Google BigQuery でお客様のアプリケーション情報を保持するデータウェアハウスを持っています。
Google BigQuery のデータウェア ハウスには 2 PB のユーザーデータが保存されています。最近、会社はユーザーベースをEU ユーザーに拡大したため、次の要件に準拠する必要があります。
– ユーザーの要求に応じてすべてのユーザーアカウント情報を削除することができなければならない。
– すべてのEU ユーザーデータはEU ユーザー専用の単一地域に保存されなければならない。
どのアクションを取るべきでしょうか?(回答を 2つ選択してください)
- A. Google BigQuery のフェデレーション クエリを使用して Google Cloud Storage からデータを照会します。
- B. EU ユーザーのみの情報を保持するデータセットを EU リージョンに作成します。
- C. EU ユーザーのみの情報を保存する Google Cloud Storage のバケットを EU リージョンに作成します。
- D. ユーザーのレコードを除外して Google Cloud Dataflow パイプラインにデータを再アップロードします。
- E. Google BigQuery の DML ステートメントを使用してリクエストに基づいてユーザーレコードを更新/削除します。
Correct Answer: C、E
Reference contents:
– データ ウェアハウス使用者のための BigQuery | Solutions | Google Cloud
Question 64
Google App Engine standard 構成は次になります。
– service: production
– instance_class: B1
アプリケーションを 5つのインスタンスに制限したいとします。
どのコードスニペットを設定に含めるべきでしょうか?
- A. manual_scaling: instances: 5 min_pending_latency: 30ms
- B. manual_scaling: max_instances: 5 idle_timeout: 10m
- C. basic_scaling: instances: 5 min_pending_latency: 30ms
- D. basic_scaling: max_instances: 5 idle_timeout: 10m
Correct Answer: C → D
Reference contents:
– app.yaml リファレンス #スケーリングの要素
Question 65
分析システムは Google BigQuery データセットに対してクエリを実行します。
SQL クエリはバッチで実行され、SQL ファイルの内容を Google BigQuery CLI に渡します。その後、Google BigQuery CLI の出力を別のプロセスにリダイレクトしますがクエリの実行時に Google BigQuery CLI からパーミッションエラーが発生しており、この問題を解決したいと考えています。
どうすればよいでしょうか?
- A.サービスアカウントに Google BigQuery Data Viewer と Google BigQuery Job User の役割を付与します。
- B.サービスアカウントに Google BigQuery データ編集者と Google BigQuery データ閲覧者 の役割を付与します。
- C. SQL クエリから Google BigQuery にビューを作成し、CLI のビューからSELECT *を実行します。
- D. Google BigQuery で新しいデータセットを作成し、ソーステーブルを新しいデータセットにコピーするCLIから新しいデータセットとテーブルをクエリします。
Correct Answer: B → A
Reference contents:
– 事前定義ロールと権限 #BigQuery の IAM 事前定義ロール | BigQuery
Question 66
使用しているアプリケーションは Google Compute Engine で実行されており、少数のリクエストに対して持続的な障害を示しています。
原因を 1つの Google Compute Engine インスタンスに絞り込みましたがそのインスタンスはSSH に反応しません。
何をすべきでしょうか?
- A. マシンを再起動します。
- B. シリアルポートの出力を有効にして確認します。
- C. マシンを削除して、新しいマシンを作成します。
- D. ディスクのスナップショットを作成し、新しいマシンに接続します。
Correct Answer: A → B
Reference contents:
– SSH のトラブルシューティング #シリアル コンソールで問題をデバッグする | Compute Engine ドキュメント
Question 67
Google Compute Engine のインスタンス グループが全体の CPU 使用率に応じて自動的にスケーリングされるように設定しました。
しかし、クラスタがインスタンスの追加を終了する前にアプリケーションのレスポンス レイテンシーが急激に増加します。インスタンス グループ オートスケーラーの構成を変更することでエンドユーザーにより一貫したレイテンシー エクスペリエンスを提供したいと考えています。
どの構成変更を行うべきでしょうか?(回答を 2つ選択してください)
- A. インスタンス グループ テンプレートに「AUTOSCALE」というラベルを追加します。
- B. グループに追加したインスタンスのクールダウン期間を短くします。
- C. インスタンス グループ オートスケーラーの目標 CPU 使用量を増やします。
- D. インスタンス グループ オートスケーラーの目標 CPU 使用量を減らします。
- E. インスタンス グループ内の個々のVMのヘルスチェックを削除します。
Correct Answer: A、C → B、D
Reference contents:
– インスタンスのグループの自動スケーリング #クールダウン期間 | Compute Engine ドキュメント
– CPU 使用率に基づくスケーリング | Compute Engine ドキュメント
Question 68
マネージド インスタンス グループ(MIGs)によって管理されているアプリケーションを持っています。
アプリケーションの新しいバージョンをデプロイするときはコストを最小限に抑え、インスタンス数を増やしてはいけません。各新しいインスタンスが作成されたときに新しいインスタンスが健全な場合にのみデプロイが継続されるようにしたいと考えています。
何をすべきでしょうか?
- A. maxSurge を 1、maxUnavailableを 0 に設定し、rolling-action を実行します。
- B. maxSurge を 0、maxUnavailableを 1 に設定し、rolling-action を実行します。
- C. maxHealthy を 1、maxUnhealthyを 0 に設定し、rolling-action を実行します。
- D. maxHealthy を 0、maxUnhealthyを 1 に設定し、rolling-action を実行します。
Correct Answer: A → B
Reference contents:
– MIG のインスタンスに更新を自動的にロールアウトする | Google Cloud
Question 69
アプリケーションではホストの Google Compute Engine 仮想マシン インスタンスに保存されている認証情報を介してサービス アカウントを GCP プロダクトに対して認証する必要があります。
これらの認証情報をホスト インスタンスにできるだけ安全に配布する必要があります。
何をするべきでしょうか?
- A. HTTP 署名付きURLを使用して必要なリソースへのアクセスを安全に提供します。
- B. 認証情報 JSONファイルをアプリケーションのソースリポジトリにコミットし、CI/CD プロセスでインスタンスにデプロイされるソフトウェアと一緒にパッケージ化します。
- C. インスタンスがデプロイされた後に Google Cloud Console からP12 ファイルを生成してアプリケーションを起動する前に認証情報をホスト インスタンスにコピーします。
- D. インスタンスのサービス アカウントの デフォルト認証情報を使用して必要なリソースを認証します。
Correct Answer: B
Reference contents:
– Google Compute Engine に対する承認リクエスト | Compute Engine ドキュメント | Google Cloud
Question 70
アプリケーションは Google Kubernetes Engine(GKE)クラスタにデプロイされています。
このアプリケーションを Cloud Load Balancing HTTP(S) ロードバランサーの後ろで公開したいと考えています。
どうすればいいのでしょうか?
- A. GKE Ingress リソースを構成します。
- B. GKE サービス リソースを構成します。
- C.タイプが Load Balancer の GKE Ingress リソースを構成します。
- D.タイプが Load Balancer の GKE サービスリソースを構成します。
Correct Answer: A
Reference contents:
– HTTP(S) 負荷分散用 GKE Ingress | Google Cloud
Question 71
会社はオンプレミスの Hadoop 環境をクラウドに移行しようと計画しています。
HDFS に保存されているデータのストレージ コストの増加とメンテナンスは、貴社にとって大きな懸念事項です。また、既存のデータ分析ジョブや既存のアーキテクチャの変更を最小限に抑えたいと考えています。
どのように移行を進めるべきでしょうか?
- A. Hadoopに保存されているデータをGoogle BigQueryに移行します。ジョブを変更して、オンプレミスのHadoop 環境ではなく、Google BigQueryから情報をソースするようにします。
- B. コストを節約するために SSD ではなく HDD を使用してGoogle Compute Engine インスタンスを作成します。その後、Google Compute Engine インスタンスで既存環境の新しい環境へのフル マイグレーションを実行します。
- C. Google Cloud Platform に Google Cloud Dataproc クラスタを作成し、Hadoop 環境を新しい Google Cloud Dataproc クラスタに移行します。ストレージコストを節約するために HDFS データをより大きな HDD に移動します。
- D. Google Cloud Platform に Google Cloud Dataproc クラスタを作成し、Hadoop コードオブジェクトを新しいクラスタに移行します。データを Google Cloud Storage に移動し、Google Cloud Dataproc コネクタを活用してそのデータ上でジョブを実行します。
Correct Answer: D
Question 72
データは Google Cloud Storage バケットに保存されます。
仲間の開発者から Google Cloud Storage からダウンロードしたデータがAPI のパフォーマンスを低下させていると報告されています。
この問題を調査して Google Cloud Platform サポートチームに詳細を提供したいと考えています。
どのコマンドを実行しますか?
- A. gsutil test “”o output.json gs://my-bucket
- B. gsutil perfdiag “”o output.json gs://my-bucket
- C. gcloud compute scp example-instance:~/test-data “”o output.json gs://my-bucket
- D. gcloud services test “”o output.json gs://my-bucket
Correct Answer: B
Reference contents:
– Sometimes get super-slow download rates from Google Cloud Storage, severely impacting workflow
– perfdiag – Run performance diagnostic | Cloud Storage
Question 73
Google Cloud Build build を使用して、Docker イメージを開発環境、テスト環境、本番環境に推進しています。
これらの環境のそれぞれに同じDocker イメージがデプロイされていることを確認する必要があります。
ビルド内のDocker イメージはどのように識別する必要がありますか?
- A. 最新のDocker イメージ タグを使用します。
- B. 固有のDocker イメージ名を使用します。
- C. Docker イメージのダイジェストを使用します。
- D. セマンティック バージョンのDocker イメージ タグを使用します。
Correct Answer: D
Question 74
会社ではレポートを Google Cloud Storage バケットにアップロードするアプリケーションを作成しました。
レポートがバケットにアップロードされたら Google Cloud Pub/Sub 通知にメッセージを公開し、実装に手間がかからないソリューションを実装したいと考えています。
どうすればいいのでしょうか?
- A. オブジェクトが変更されたときに Google Cloud Pub/Sub 通知をトリガーするように Google Cloud Storage バケットを設定します。
- B. ファイルを受信するための Google App Engine アプリケーションを作成し、ファイルを受信したら Google Cloud Pub/Sub 通知にメッセージを公開します。
- C. Google Cloud Storage バケットによってトリガーされる Google Cloud Function を作成します。Google Cloud Function で Google Cloud Pub/Sub 通知にメッセージを公開します。
- D. ファイルを受信するために Google Kubernetes Engine クラスタにデプロイされたアプリケーションを作成し、ファイルを受信したら Google Cloud Pub/Sub 通知にメッセージを公開します。
Correct Answer: C → A
Reference contents:
– Cloud Storage の Pub/Sub 通知 | Google Cloud
Question 75
チームメイトは Google Cloud Datastore のアカウント残高にクレジットを追加している次のコードを確認するように依頼がありました。
チームメイトにどのような改善を提案しますか?
public Entity creditAccount (long accountId, long creditAmount) {
Entity account = datastore.get
(keyFactory.newKey (accountid)) ;
account = Entity.builder (account).set(
"balance", account.getLong ("balance") + credit Amount) .build()
datastore.put (account);
return account;
}- A. 祖先(ancestor)クエリで実体を取得します。
- B. エンティティを取得してトランザクションに入れます。
- C. 強く一貫性のあるトランザクションデータベースを使用します。
- D. 関数からアカウント エンティティを返しません。
Correct Answer: A → B
Reference contents:
– トランザクション | Cloud Datastore ドキュメント
Question 76
会社は Google Cloud Source Repositories リポジトリにソースコードを保存しています。
会社はリポジトリにコミットされた各ソースコード上でコードを構築してテストしたいと考えており、管理されていてオペレーションのオーバーヘッドが最小限であるソリューションを必要としています。
どの方法を使うべきでしょうか?
- A. ソースコードのコミットごとにトリガーを設定した Google Cloud Build を使用する。
- B. Google Cloud Marketplace 経由でデプロイされたJenkins を使用し、ソースコードのコミットを監視するように設定します。
- C. ソースコードのコミットを監視するように設定されたオープンソースの継続的統合ツールを備えた Google Compute Engine 仮想マシンインスタンスを使用します。
- D. ソースコードのコミットトリガーを使用して Google App Engine サービスがソースコードをビルドするきっかけとなるメッセージを Google Cloud Pub/Subトピックにプッシュします。
Correct Answer: A
Question 77
プロジェクト Aで Google Compute Engine がホストするアプリケーションを作成しており、プロジェクト Bの Google Cloud Pub/Sub トピックに対して安全に認証する必要があります。
何をするべきでしょうか?
- A. プロジェクト Bが所有するサービス アカウントでインスタンスを構成し、そのサービスアカウントを Google Cloud Pub/Sub パブリッシャーとしてプロジェクト Aに追加します。
- B. プロジェクト Aが所有するサービス アカウントでインスタンスを構成し、サービス アカウントをトピックのパブリッシャーとして追加します。
- C. アプリケーションのデフォルト認証情報を、プロジェクト Bが所有するサービス アカウントの秘密鍵を使用するように設定し、そのサービス アカウントを Google Cloud Pub/Sub のパブリッシャーとしてプロジェクト Aに追加します。
- D. アプリケーションのデフォルトの認証情報を構成して、プロジェクトAが所有するサービス アカウントのプライベートキーを使用し、サービス アカウントをトピックのパブリッシャーとして追加します。
Correct Answer: B
Question 78
Google Compute Engine で財務部門向けの企業ツールを開発しています。
このツールではユーザーを認証し、財務部門に所属していることを確認する必要があります。会社の従業員は全員 G Suite を使用しています。
何をすべきでしょうか?
- A. HTTP (s) ロードバランサーで Google Cloud Identity-Aware Proxy を有効にし、財務部門のユーザーを含む Google グループへのアクセスを制限します。提供された JSON Web Token をアプリケーション内で確認します。
- B. HTTP (s) ロードバランサーで Google Cloud Identity-Aware Proxy を有効にし、財務部門のユーザーを含む Google グループへのアクセスを制限する。財務チームの全員にクライアントサイド証明書を発行してアプリケーション内で証明書を検証します。
- C. Google Cloud Armor セキュリティ ポリシーを設定して企業の IP アドレス範囲のみにアクセスを制限します。提供された JSON Web Token をアプリケーション内で確認します。
- D. Google Cloud Armor セキュリティ ポリシーを設定して企業の IP アドレス範囲のみにアクセスを制限します。財務チームの全員にクライアントサイド証明書を発行してアプリケーション内で証明書を検証します。
Correct Answer: C → A
Reference contents:
– ユーザーを認証するための Google ID トークンの使用
Question 79
API バックエンドが複数のクラウド プロバイダ上で実行されており、API のネットワーク遅延に関するレポートを作成したいとします。
どのステップを実行しますか?(回答を 2つ選択してください)
- A. Zipkin コレクターを使ってデータを収集します。
- B. Fluentd エージェントを使用してデータを収集します。
- C. Stackdriver Trace を使用してレポートを生成します。
- D. Stackdriver Debugger を使用してレポートを生成します。
- E. スStackdriver Profiler を使用してレポートを生成します。
Correct Answer: C、E → A、C
Reference contents:
– Cloud Trace と Zipkin の使用
Question 80
この問題については HipLocal のケーススタディを参照してください。
HipLocal はどのデータベースをユーザーアクティビティの保存に使用するべきでしょうか?
- A. Google BigQuery
- B. Google Cloud SQL
- C. Google Cloud Spanner
- D. Google Cloud Datastore
Correct Answer: C
Question 81
この問題については HipLocal のケーススタディを参照してください。
HipLocal はアクセス コントロールを構成しています。
どのファイアウォール構成を実装すべきでしょうか?
- A. ポート 443 のすべてのトラフィックをブロックします。
- B. ネットワークへのすべてのトラフィックを許可します。
- C. 特定のタグに対してポート 443 のトラフィックを許可します。
- D. ポート 443 のすべてのトラフィックをネットワークに許可します。
Correct Answer: C
Question 82
この問題については HipLocal のケーススタディを参照してください。
HipLocal のデータサイエンスチームはユーザーレビューの分析を希望しています。
どのようにデータを準備すればよいのでしょうか?
- A. Google Cloud Data Loss Prevention API を使用してレビューデータ セットのリダクションを行ないます。
- B. Google Cloud Data Loss Prevention API を使用してレビューデータセットを匿名化します。
- C. Google Cloud Natural Language Processing API を使用してレビュー データセットを再編集します。
- D. Google Cloud Natural Language Processing API を使用してレビュー データセットの匿名化します。
Correct Answer: D
Question 83
この問題については HipLocal のケーススタディを参照してください。
HipLocal がアプリケーションの状態を保存し、規定のビジネス要件を満たすためにはどのデータベース サービスに移行すべきでしょうか?
- A. Google Cloud Spanner
- B. Google Cloud Datastore
- C.キャッシュとしての Google Cloud Memorystore
- D.リージョンごとに個別の Google Cloud SQL クラスタ
Correct Answer: A
Question 84
本番環境にアプリケーションを導入しています。
新しいバージョンがデプロイされたとき、すべての本番環境のトラフィックが新しいバージョンのアプリケーションにルーティングされるようにしたいと考えています。また、新バージョンで問題が発生した場合に前のバージョンに戻せるように、前のバージョンをデプロイしておきたいと考えています。
どのような展開戦略をとるべきでしょうか。
- A. ブルー/グリーン(Blue/green)デプロイメント
- B. カナリア(Canary)デプロイメント
- C. ローリング(Rolling)デプロイメント
- D. 再作成(Recreate) デプロイメント
Correct Answer: C → A
Comments are closed