![[GCP] Google Cloud Certified:Professional Cloud Architect](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_professional-cloud-architect-1200x675.jpg)
※ 他の問題集は「タグ:Professional Cloud Architect の模擬問題集」から一覧いただけます。
Google Cloud 認定資格 – Professional Cloud Architect – Practice Exam 模擬問題集(全 61問)
Question 1
開発マネージャーが新しいアプリケーションを構築しています。
アプリケーションには次の要件になります。
- クラウド ポータビリティのためのオープンソース技術をベース
- 需要に応じてコンピュート容量を動的にスケーリング
- 継続的なソフトウェア デリバリをサポート
- 同じアプリケーションスタックの複数の分離されたコピーの実行
- 動的テンプレートを使用したアプリケーションバンドルの展開
- URL に基づいてネットワーク トラフィックを特定のサービスにルーティング
どの技術の組み合わせが開発マネージャーの要求をすべて満たすことができるでしょうか?
- A. Google Container Engine、Jenkins、Helm
- B. Google Container Engine、Cloud Load Balancing
- C. Google Compute Engine、Google Cloud Deployment Manager
- D. Google Compute Engine、Jenkins、Google Cloud Load Balancing
Correct Answer: A
Kubernetes を管理するためのHelm
Kubernetes はURLをベースに別の場所(パス)にトラフィックをルーティングすることができます
Reference contents:
– Ingress による HTTP(S) 負荷分散の設定
Question 2
この問題については Dress4Win のケーススタディを参照してください。
Dress4Win 社ではエンドポイントの 100%をカバーするエンドツーエンドのテストを実施しています。
Dress4Win はクラウドへの移行によって新たなバグが発生しないことを確認したいと考えています。
開発者は障害を防ぐためにどのような追加のテスト方法を採用すべきでしょうか?
- A. クラウドのステージング 環境でエンドツーエンドのテストを実行して、コードが意図した通りに動作しているかどうかを判断する必要があります。
- B. クラウドのステージング 環境でユニットテストと実稼働規模の負荷テストを追加するべきです。
- C. アプリケーション コードのエラーを表示するために、アプリケーション コード上で Google Stackdriver Debugger を有効にします。
- D. カナリア テストを追加して、開発者が新しいリリースがレイテンシにどの程度の影響を与えるかを測定できるようにすべきです。
Correct Answer: B
Question 3
この問題については TerramEarth のケーススタディを参照してください。
TerramEarth 社は現場にある 2,000万台の車両をすべてクラウドに接続する計画です。
これにより、1時間に 40TB、1秒間に 2,000万件の 600バイトのレコードが記録される量が増加することを予測されてます。
データの取り込みはをどのように設計するべきでしょうか?
- A. 車両は Google Cloud Storage に直接データを書き込みます。
- B. 車両は Google Cloud Pub/Sub に直接データを書き込みます。
- C. 車両は Google BigQuery に直接データをストリーミングします。
- D. 車両は既存のシステム(FTP)を利用してデータを書き続けます。
Correct Answer: B
Reference contents:
– データ ライフサイクル
– Cloud IoT Core での Connected Vehicle Platform の設計
Question 4
この問題については TerramEarth のケーススタディを参照してください。
TerramEarth 社はデータファイルを Google Cloud Storage(GCS)に保存することを決定しました。
1年間のデータを保存し、ファイルの保存コストを最小限に抑えるために GCS のライフサイクル管理を設定する必要があります。
どのようなアクションを取るべきでしょうか?
- A. 1番目に Age: 30, Storage Class: Standard, Action: Set to Coldline、2番目に Age: 365, Storage Class: Coldline, Action: Delete の GCS ライフサイクル管理を作成します。
- B. 1番目に Age: 30, Storage Class: Coldline, Action: Set to Nearline、2番目に Age: 91, Storage Class: Coldline, Action: Set to Nearline の GCS ライフサイクル管理を作成します。
- C. 1番目に Age: 90, Storage Class: Standard, Action: Set to Nearline、2番目に Age: 91, Storage Class: Nearline, Action: Set to Coldline の GCS ライフサイクル管理を作成します。
- D. 1番目に Age: 30, Storage Class: Standard, Action: Set to Coldline、2番目に Age: 365, Storage Class: Nearline, Action: Delete の GCS ライフサイクル管理を作成します。
Correct Answer: A
Question 5
Google Compute Engine VM から Google BigQuery に接続するための Python スクリプトを書いています。
スクリプトは Google BigQuery に接続できないというエラー表示されています。
スクリプトを修正するにはどうすればいいですか?
- A. Python 用の最新の Google BigQuery API クライアント ライブラリをインストールします。
- B. Google BigQuery アクセス スコープを有効にした新しいVM 上でスクリプトを実行します。
- C. Google BigQuery アクセスを持つ新しいサービス アカウントを作成し、そのユーザーでスクリプトを実行します。
- D. gcloud コンポーネント インストール bq というコマンドを使用して、gccloud 用の bq コンポーネントをインストールします。
Correct Answer: B
このエラーはアクセススコープの問題が原因である可能性が最も高いです。 新しいインスタンスを作成すると、デフォルト設定の Google Compute Engine にはサービスアカウントがありますが、GoogleBigQuery を含むほとんどのサービス アカウントが有効になっていません。 インスタンスの作成ほとんどのアクセスはデフォルトで有効になっていません。サービス アカウントを持っていますが、インスタンスを停止、編集、変更し、再起動してスコープ アクセスを有効にする権限(スコープ)がありません。 もちろん、Google BigQuery アクセス スコープを有効にし、新しいVMでスクリプトを実行するとスクリプトが機能します。
Reference contents:
– サービス アカウント
Question 6
この問題については、Dress4Win のケーススタディを参照してください。
監査時に法的に準拠するためには Dress4Win 社は Google Cloud 上のリソースの構成またはメタデータを変更するすべての管理アクションにインサイトを与えることができなければなりません。
何をすべきでしょうか?
- A. Stackdriver Trace を使用して、トレース リスト解析を作成します。
- B. Stackdriver Monitoring を使用して、プロジェクトのアクティビティのダッシュボードを作成します。
- C. すべてのプロジェクトで Google Cloud Identity-Aware Proxy を有効にし、管理者 グループをメンバーとして追加します。
- D. GCP Console のアクティビティページと Stackdriver Logging を使用して、必要な情報を提供します。
Correct Answer: A
Reference contents:
– Cloud Audit Logs
Question 7
顧客は Google Cloud Platform 上で稼働しているゲームサーバーから複数 GBのリアルタイム キーパフォーマンス 指標(KPI)の集計値を取得し、低レイテンシでKPI を監視したいと考えています。
どのようにしてKPI をキャプチャするべきでしょうか?
- A. ゲームサーバーの時系列データを Google Cloud Bigtable に保存し、Google Data Studio を使って閲覧します。
- B. ゲームサーバーから Stackdriver にカスタムメトリクスを出力し、Stackdriver Monitoring Console でダッシュボードを作成して表示します。
- C. Google BigQuery のロードジョブをスケジュールして、Google Cloud Storage にアップロードされたアナリティクス ファイルを10分ごとにインジェストし、Google Data Studio で結果を可視化します。
- D. Google Cloud Datastore のエンティティにKPIを挿入し、Google Cloud Datalab でアドホックな分析と可視化を実行します。
Correct Answer: A
Reference contents:
– 時系列の構造
Question 8
アプリケーションは分析のために Google BigQuery にログを書き込むことになります。
各アプリケーションは独自のテーブルを持ち、45日より古いログはすべて削除する必要があります。 ストレージを最適化し、Google のベスト プラクティスに従います。
何をするべきか?
- A. テーブルの有効期限を45日に設定します。
- B. テーブルを時間パーティション化し、45日でパーティションの有効期限を設定します。
- C. Google BigQuery のデフォルトの動作に依存して、45日よりも古いアプリケーション ログを刈り取るようにします。
- D. Google BigQuery のコマンド ライン ツール (bq) を使用して、45 日より古いレコードを削除するスクリプトを作成します。
Correct Answer: B
Reference contents:
– パーティション分割テーブルの管理
Question 9
この問題については JencoMart のケーススタディを参照にしてください。
JencoMart 社のアプリケーションの Google Cloud Platform(GCP)への移行が遅々として進んでいます。インフラは図のようになっており、スループットを最大化したいと考えています。
3つの潜在的なボトルネックは何でしょうか?(回答を 3つ選択してください)
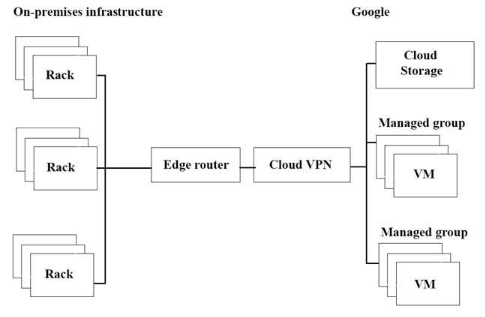
- A. オンプレミス インフラと GCP 間のインターネット接続が複雑です
- B. この作業に適していない Google Cloud Storage の階層です。
- C. スループットを制限する単一のVPNトンネルです。
- D. 長距離での操作に不向きなコピーコマンドです。
- E. GCP のVM 数は オンプレミスのマシンよりも少ないです。
- F. このタスクには適していないVMの外側に別のストレージ層です。
Correct Answer: A、C、E
Question 10
会社はオンプレミスのデータセンターをクラウドに移行しています。
移行の一環として、ワークロードのオーケストレーションのために Google Kubernetes Engine を統合し、アーキテクチャの一部もPCI DSS に準拠している必要があります。
次のうち最も正確なものはどれですか?
- A. Google App Engine は、PCI DSS ホスティングの認定を受けている GCP 上の唯一のコンピューティングプラットフォームです。
- B. Google Kubernetes Engine は、共有ホスティングと見なされるため、PCI DSS では使用できません。
- C. Google Kubernetes Engine と GCP は、PCI DSS 準拠の環境を構築するために必要なツールを提供します。
- D. GCP はPCI 準拠の認定を受けているため、すべての GoogleCloud サービスを使用できます。
Correct Answer: D
Reference contents:
– PCI DSS
Question 11
会社は予定された会議のために予約された会議室に誰かが出席しているかどうかを追跡したいと考えています。
3大陸にある 5つのオフィスには 1,000室の会議室があります。各部屋にはモーションセンサーが設置されており、毎秒ごとにその状態を報告しています。人感センサーからのデータにはセンサー IDといくつかの異なる情報が含まれています。アナリストはこのデータをアカウント所有者やオフィスの場所に関する情報と合わせて使用します。
どのデータベースタイプを使用すればよいですか?
- A. Flat file
- B. NoSQL
- C. Relational
- D. Blobstore
Correct Answer: B
リレーショナル データベースは現代のアプリケーションが直面するスケールや俊敏性の課題に対処するために設計されたものではありませんでしたし、今日利用可能な汎用的なストレージや処理能力を活用するために設計されたものでもありません。
NoSQLは次のような用途に適しています。
不正解の D: Blobstore API を使用すると、アプリケーションは Google Cloud Datastore サービスのオブジェクトに許可されているサイズよりもはるかに大きい blob と呼ばれるデータオブジェクトを提供することができます。blobは、動画ファイルや画像ファイルなどの大容量のファイルを提供したり、ユーザーが大容量のデータファイルをアップロードできるようにするのに便利です。
Reference contents:
– What is NoSQL?
Question 12
この問題については TerramEarth のケーススタディを参照してください。
データ検索を高速化するために、セルラー接続にアップグレードし、ETL プロセスにデータを転送できるようにする車両が増えます。
現在のFTP プロセスはエラーが発生しやすく、接続に失敗するとファイルの最初からデータ転送を再起動してしまうため、頻繁に発生します。ソリューションの信頼性を向上させ、セルラー接続でのデータ転送時間を最小限に抑えたいと考えています。
どうすればよいでしょうか?
- A. FTP サーバーの Google Container Engine クラスタを 1台使用します。Google Cloud Multi-Regional Storage バケットにデータを保存します。バケット内のデータを使用してETL プロセスを実行します。
- B. 異なる地域にあるFTP サーバーを実行している複数の Google Container Engine クラスタを使用します。データを米国、欧州、アジアの Multi-Regional バケットに保存します。バケット内のデータを使用してETL プロセスを実行します。
- C. 直接、HTTP (S) を介して Google API を使用して、Google Cloud Multi-Regional Storage バケットの異なる場所にファイルを転送します。バケット内のデータを使用してETL プロセスを実行します。
- D. Google APIs over HTTP(S) を使用して、米国、欧州、アジアの別のGoogle Cloud Regional Storage バケットの場所にファイルを直接転送します。各リージョナルバケットからデータを取得するためにETL プロセスを実行します。
Correct Answer: D
Reference contents:
– バケットのロケーション
Question 13
Google Cloud Bigtable を使用して Google Compute Engine 上で動作するプライマリ クラウド サービスのスケーラビリティをテストするための新しい負荷テスト ツールをQA チームが展開するのを支援しています。
それらに含まれるべき 3つの要件はどれでしょうか?(回答を 3つ選択してください)
- A. 負荷テスト環境に使用する Google Cloud プロジェクトを別途作成します。
- B. 負荷テストツールで再生するために、本番サービスにすべてのトランザクションを記録するようにインスツルメントします。
- C. 負荷テストツールが本番 環境に対して定期的に実行されるようにスケジュールを設定します。
- D. ロードテストツールとターゲットサービスに、詳細なロギングとメトリクスの収集を装備します。
- E. サービスが使用するすべてのサードパーティ製システムが高負荷を処理できることを確認します。
- F. 負荷テストで Google Cloud Bigtable のパフォーマンスが検証されていることを確認します。
Correct Answer: A、D、F
Question 14
会社の Application Reliability チームは、バックエンドサービスにデバッグ機能を追加し、最終的な分析のためにすべてのサーバーイベントを Google Cloud Storage に送信しました。イベント記録は最低でも 50 KB、最大でも 15 MB で、ピーク時には毎秒 3,000 件のイベントが発生すると予想されます。データの損失を最小限に抑えたいと考えています。
どのプロセスを実装すべきでしょうか?
- A. ファイル本体にメタ データを追加します。
- 個々のファイルを圧縮する。
- serverName-Timestamp でファイルに名前を付ける。
- バケットが 1時間よりも古い場合は新しいバケットを作成し、個々のファイルを新しいバケットに保存します。それ以外の場合は既存のバケットにファイルを保存します。
- B. 10,000イベントごとに、メタ データ用の単一マニフェスト ファイルでバッチ処理を行います。
- イベント ファイルとマニフェスト ファイルを 1つのアーカイブ ファイルに圧縮します。
- serverName-EventSequence を使用してファイルに名前を付けます。
- バケットが 1 日よりも古い場合は新しいバケットを作成し、単一のアーカイブ ファイルを新しいバケットに保存します。それ以外の場合は既存のバケットにアーカイブファイルを保存します。
- C. 個々のファイルを圧縮します。
- serverName-EventSequence を使用してファイルに名前を付けます。
- ファイルを 1つのバケットに保存します。
- 保存後、各オブジェクトにカスタムメタ データヘッダを設定します。
- D. ファイル本体にメタデータを追加します。
- 個々のファイルを圧縮します。
- ランダムな接頭辞パターンでファイルに名前を付けます.
- ファイルを1つのバケットに保存します。
Correct Answer: D
高いリクエストレートを維持するために連続的な名前の使用は避けてください。完全にランダムなオブジェクト名を使用すると、最高の負荷分散が得られます。共通の接頭辞の後のランダム性は、接頭辞の下で有効です。
Reference contents:
– リクエスト レートとアクセス配信のガイドライン
Question 15
この問題については TerramEarth のケーススタディを参照してください。
TerramEarth 社のダウンタイムを削減するためのビジネス要件を分析し、顧客の部品待ち時間を削減することで大部分の時間短縮を達成できることを発見しました。3週間の集計報告時間の削減に焦点を当てることにしました。
会社のプロセスにどのような修正を推奨しますか?
- A. CSV からバイナリ形式への移行し、FTP からSFTP トランスポートへの移行し、メトリクスの機械学習分析の開発を行います。
- B. FTP からストリーミング トランスポートへの移行し、CSV からバイナリ形式への移行し、機械学習によるメトリクス分析の開発を行います。
- C. フリートセルラーの接続性を 80%に高め、FTP からストリーミング トランスポートに移行し、メトリクスの機械学習分析の開発を行います。
- D. FTP からSFTP トランスポートへの移行し、機械学習分析によるメトリクスの開発を行い、ディーラーのローカル在庫を一定の割合で増加させます。
Correct Answer: C
Avro バイナリ形式は圧縮されたデータを読み込むのに適した形式です。Avro データはデータ ブロックが圧縮されている場合でも、データを並行して読み込むことができるため、読み込みが高速になります。
Google Cloud Storage は、HTTP チャンク化された転送エンコーディングに基づいた gsutil ツールまたは boto ライブラリを使用したストリーミング転送をサポートしています。ストリーミング データを使用すると、データを最初に別のファイルに保存しなくても、データが利用可能になったらすぐに Google Cloud Storage アカウントとの間でデータをストリーミングすることができます。ストリーミング転送は、データを生成するプロセスがあり、アップロードする前にデータをローカルにバッファリングしたくない場合や、計算パイプラインの結果を直接 Google Cloud Storage に送信したい場合に便利です。
Reference contents:
– ストリーミング転送
– データの読み込みの概要
Question 16
この問題については Mountkirk Games のケーススタディを参照してください。
Mountkirk Games 社のデータベース ワークロードの技術的なアーキテクチャを分析し、定義する必要があります。
ビジネスと技術的な要件を考慮して何をすべきでしょうか?
- A. 時系列データには Google Cloud SQL を使用し、履歴データのクエリには Google Cloud Bigtable を使用します。
- B. Google Cloud SQL を MySQL の代わりに使用し、履歴データのクエリには Google Cloud Spanner を使用します。
- C. Google Cloud Bigtable を MySQL の代わりに使用し、履歴データのクエリには Google BigQuery を使用します。
- D. 時系列データには Google Cloud Bigtable を使用し、トランザクションデータには Google Cloud Spannerを使用し、履歴データのクエリには Google BigQuery を使用します。
Correct Answer: D
Reference contents:
– 時系列データ用のスキーマ設計
Question 17
この問題については Mountkirk Games のケーススタディを参照してください。
Mountkirk Games 社はモバイルネットワークの遅延の変化に対する分析プラットフォームの復元力をテストする方法を設計することを望んでいます。
何をするべきでしょうか?
- A. モバイルクライアント分析トラフィックに追加のレイテンシを注入できるゲーム分析プラットフォームに障害注入ソフトウェアをデプロイします。
- B. プレーヤーのモバイルデバイスで実行され、世界中の Google CloudPlatform リージョンで実行されている分析エンドポイントから応答時間を収集するゲームのオプトインベータを作成します。
- C. Google Compute Engine VM 上の携帯電話エミュレーターから実行できるテストクライアントを構築し、世界中の Google Cloud Platform リージョンで複数のコピーを実行して、現実的なトラフィックを生成します。
- D. モバイルデバイスからアップロードされた分析ファイルの処理を開始する前に、ランダムな量の遅延を導入する機能を追加します。
Correct Answer: B
Question 18
この問題については Dress4Win のケーススタディを参照してください。
Dress4Win 社の新しいアプリケーションの経験の一部として、顧客が自分自身の画像をアップロードすることを可能にします。顧客は誰がこれらの画像を見ることができるかを排他的に制御することができます。顧客は最小限の待ち時間で画像をアップロードすることができ、また、ログインしたときにメイン アプリケーションのページに素早く画像を表示することができるはずです。
どのような構成を使用するべきでしょうか?
- A. 分散ファイルシステムを使用して顧客の画像を保存します。ストレージの必要性が高まると、より多くの永続的なディスクおよび/またはノードを追加します。各顧客に一意のID を割り当て、各ファイルの所有者属性を設定することで、画像のプライバシーを確保します。
- B. 画像ファイルを Google Cloud Storage バケットに保存します。Google Cloud Storage にアップロードされた画像に顧客固有のID を含むカスタムメタデータを追加します。
- C. 画像ファイルを Google Cloud Storage バケットに保存します。Google Cloud Datastore を使用して各顧客のID と画像ファイルをマッピングしたメタデータを管理します。
- D. 分散ファイルシステムを使用して顧客の画像を保存します。ストレージのニーズが増えたら、永続的なディスクおよび/またはノードを追加する。Google Cloud SQL データベースを使用して各顧客のID と顧客の画像ファイルをマッピングするメタデータを維持します。
Correct Answer: C
Question 19
正確でリアルタイムな天気図アプリケーションのパフォーマンスを最適化したいと考えています。データは、タイムスタンプとセンサーの読み取り値の形式で、毎秒 10回の読み取り値を送信する 50,000個のセンサーから得られます。
データはどこに保存するべきでしょうか?
- A. Google BigQuery
- B. Google Cloud SQL
- C. Google Cloud Bigtable
- D. Google Cloud Storage
Correct Answer: C
時系列データであるSo Big Tableです。
Google Cloud Bigtable は、リアルタイムアクセスとアナリティクスのワークロードの両方に適したスケーラブルでフルマネージドな NoSQL ワイドカラムデータベースです。
次に適しています。
– 低レイテンシの読み書きアクセス
– ハイスループット解析
– ネイティブ時系列サポート
– 一般的なワークロード。
– IoT、金融、アドテク
– パーソナライゼーション、レコメンデーション
– モニタリング
– 地理空間データセット
– グラフ
Reference contents:
– 時系列データ用のスキーマ設計
– クラウド ストレージ プロダクト
Question 20
この問題については TerramEarth のケーススタディを参照してください。
開発チームは、車両データを取得するための構造化されたAPI を作成しました。サードパーティがこの車両イベントデータを使用する販売店向けのツールを開発できるようにこのデータに対する権限委譲をサポートしたいと考えています。
どうすればよいでしょうか?
- A. OAuth 対応のアクセス制御システムを構築するか、活用します。
- B. 認証システムに SAML 2.0 SSO 互換性を構築します。
- C. パートナーシステムの送信元 IP アドレスに基づいてデータアクセスを制限します。
- D. 信頼されたサードパーティに渡すことができる、各ディーラーの二次認証情報を作成します。
Correct Answer: A
OAuth2 Cloud Platform API は OAuth 2.0 をサポートしており、スコープはサポートされているメソッドに対してきめ細かな認証を提供します。Google Cloud Platform は、サービス アカウント OAuth とユーザーアカウント OAuth の両方をサポートしており、3本足のOAuth とも呼ばれています。
Reference contents:
– エンタープライズ企業のベスト プラクティス
Question 21
アーキテクチャではプロジェクト内のすべての管理者アクティビティとVM システムのログを一元的に収集する必要があります。
VM とサービスの両方からこれらのログをどのように収集するべきでしょうか?
- A. 管理者とVM のシステムログはすべて Stackdriver が自動的に収集します。
- B. Stackdriver はほとんどのサービスの管理者活動ログを自動的に収集します。システムログを収集するには、各インスタンスに Stackdriver Logging エージェントをインストールする必要があります。
- C. カスタム syslogd コンピューティング インスタンスを起動し、GCP プロジェクトとVM がすべてのログをそこに転送するように設定します。
- D. 1つのコンピューティング インスタンスに Stackdriver Logging エージェントをインストールし、環境のすべての監査ログとアクセスログを収集するようにします。
Correct Answer: B
Reference contents:
– デフォルトの Logging エージェントのログ
Question 22
顧客は認証レイヤーの耐障害性テストを行いたいと考えています。
これは Google Cloud SQL インスタンスから読み書きするパブリック REST API を提供する地域の管理されたインスタンス グループで構成されています。
どうすればよいでしょうか?
- A. 災害シミュレーション演習をスケジュールして、ゾーン内のすべての VM をシャットダウンして、アプリケーションがどのように動作するかを確認します。
- B. VM に侵入検知ソフトウェアを導入し、不正アクセスを検知してログに記録します。
- C. Google Cloud SQL インスタンス用の赤いレプリカをマスターとは異なるゾーンに設定し、REST API の KPI を監視しながら手動でフェイルオーバーをトリガーします。
- D. セキュリティ会社と提携して、悪意のあるウェブサイトのユーザーの認証データを検索し、見つかった場合に通知するウェブスクレイプを実行します。
Correct Answer: A
Question 23
ニュース ティードのウェブサービスでは Google App Engine 上で以下のコードが実行されています。
ピークロード時にユーザーから「既に閲覧したニュース記事が表示される」との報告があります。
この問題の最も可能性の高い原因はどれでしょうか?
import news
from flask import Flask, redirect, request
from flask.ext.api import status
from google.appengine.api import users
app = Flask (_name_)
sessions = { }
@app.route ("/")
def homepage():
user = users.get_current_user()
if not user:
return "Invalid login",
status.HTTP_401_UNAUTHORIZED
if user not in sessions :
sessions (user] = { "viewed": []}
news_articles = news.get_new_news (user, sessions [user] ["viewed"])
sessions [user] ["viewed"] + [n["id"] for n in news_articles]
return news.render (news_articles)
if _name_ == "_main_":
app.run()- A. セッション変数は単一のインスタンスだけがローカルです。
- B. セッション変数が Google Cloud Datastore で上書きされている。
- C. キャッシングを防ぐために API のURLを変更する必要があります。
- D. キャッシングを停止するに HTTP Expires ヘッダーを-1に設定する必要があります。
Correct Answer: A
Reference contents:
– Google App Engine Cache List in Session Variable
Question 24
この問題については Dress4Win のケーススタディを参照してください。Dress4Win 社のクラウド移行計画の一環として、トラフィック負荷の急増に対応できるように管理されたロギングと監視システムをセットアップできるように次のことを確実にしたいと考えています。
– 1日の使用量の増減に対応するためにインフラストラクチャのスケールアップやスケールダウンが必要になったときに通知を受けることができる。
– アプリケーションがエラーを報告すると管理者に自動的に通知される。
– 管理者は集約されたログをフィルタリングして、多くのホストにまたがるアプリケーションの一部をデバッグすることができる。
どの Google StackDriver 機能を使うべきでしょうか?
- A. Logging、Alerts、Insights、Debug
- B. Monitoring、Logging、Debug、Error Report
- C. Monitoring、Logging、Alerts、Error Reporting
- D. Monitoring、Trace、Debug、Logging
Correct Answer: B
Question 25
企業はクラウドへの移行に成功し、データストリームを分析して運用を最適化したいと考えています。
この分析のための既存のコードを持っていないため、あらゆるオプションを検討しています。これらのオプションには、バッチ処理とストリーム処理を組み合わせたものが含まれます。
これにはどのテクノロジーを使用すべきでしょうか?
- A. Google Cloud Dataproc
- B. Google Cloud Dataflow
- C. Google Container Engine と Google Cloud Bigtable
- D. Google Compute Engine と Google BigQuery
Correct Answer: B
Google Cloud Dataflow は、バッチとストリームの両方を処理するためのものです。
Google Cloud Dataflowは、ストリーム(リアルタイム)モードとバッチ(履歴)モードのデータを同等の信頼性と表現力で変換し、豊かにするためのフルマネージド サービスです。 – これ以上の複雑な回避策や妥協は必要ありません。
Reference contents:
– Dataflow
Question 26
この問題については Mountkirk Games のケーススタディを参照してください。
Mountkirk Games 社は新しいゲームのためにリアルタイム分析プラットフォームを設定したいと考えていますが、新しいプラットフォームは技術的な要件を満たす必要があります。
Google テクノロジーのどの組み合わせが要件をすべて満たすでしょうか?
- A. Google Container Engine、Google Cloud Pub/Sub、Google Cloud SQL
- B. Google Cloud Dataflow、Google Cloud Storage、Google Cloud Pub/Sub、Google BigQuery
- C. Google Cloud SQL、Google Cloud Storage、Google Cloud Pub/Sub、Google Cloud Dataflow
- D. Google Cloud Dataproc、Google Cloud Pub/Sub、Google Cloud SQL、Google Cloud Dataflow
- E. Google Cloud Pub/Sub、Google Compute Engine、Google Cloud Storage、Google Cloud Dataproc
Correct Answer: B
リアルタイムではストリーム/メッセージングなので、pub/sub、Google BigQuery によるアナリティクスを必要とします。
Google 独自の高速プライベート ネットワークを搭載した Google Cloud Pub/Sub を使用して、世界中のどこからでも毎秒数百万件のストリーミング イベントを取り込みます。Google Cloud Dataflow を使用してストリームを処理し、信頼性の高く、正確に 1回限りの低レイテンシーのデータ変換を実現します。変換されたデータをクラウドネイティブのデータウェアハウス サービスである Google BigQuery にストリーム配信して SQL や一般的な可視化ツールを使ってすぐに分析することができます。
Reference contents:
– ストリーム分析
Question 27
会社はヘルスケアの新興企業を買収したため、顧客の医療情報を作成時に応じて最大 4年間保持しなければなりません。会社方針はこのデータを安全に保持し、規制が許せばすぐに削除することです。
どちらのアプローチを取るべきでしょうか?
- A. Google ドライブ にデータを保存し、期限が切れたら手動でレコードを削除します。
- B. Google Cloud Data Loss Prevention API を使用してデータを匿名化し、無期限に保存します。
- C. Google Cloud Storage を使用してデータを保存し、ライフサイクル管理で期限が切れたらファイルを削除します。
- D. Google Cloud Storage にデータを保存し、毎晩バッチ スクリプトを実行し、期限切れのデータをすべて削除します。
Correct Answer: C
Reference contents:
– オブジェクトのライフサイクル管理
Question 28
この問題については、Dress4Win のケーススタディを参照してください。
Dress4Win 社ではオペレーション エンジニアがデータベースのバックアップファイルのコピーをリモートでアーカイブするための低コストのソリューションを作成したいと考えています。
データベースファイルは現在のデータセンターに保存されている圧縮されたtar ファイルです。
どのように進めるべきでしょうか?
- A. gsutil を使用して cron スクリプトを作成し、ファイルを Google Cloud Coldline Storage バケットにコピーします。
- B. gsutil を使用して cron スクリプトを作成し、ファイルを Google Cloud Regional Storage バケットにコピーします。
- C. Google Cloud Storage Transfer Service ジョブを作成して、ファイルを Google Cloud Coldline Storage バケットにコピーします。
- D. Google Cloud Storage Transfer Service ジョブを作成して、ファイルを Google Cloud Regional Storage バケットにコピーします。
Correct Answer: A
gsutil またはストレージ転送サービスを使用するかどうかを決定する際には、これらの経験則に従ってください。
− オンプレミスの場所からデータを転送する場合は、gsutil を使用してください。別のクラウドストレージプロバイダからデータを転送する場合は、Google Cloud Storage Transfer Service を使用してください。
– それ以外の場合は、特定のシナリオに関して両方のツールを評価してください。
このガイダンスを出発点として使用してください。転送シナリオの具体的な詳細は、どちらのツールがより適切かを判断するのにも役立ちます。
Reference contents:
– Storage Transfer Service: 概要
Question 29
この問題については、Dress4Win のケーススタディを参照してください。
Dress4Win 社のセキュリティ チームは Google Cloud Platform(GCP)上の本番用VM への外部 SSH アクセスを無効にしています。
運用チームはVM のリモート管理、Docker コンテナの構築、プッシュ、Google Cloud Storage オブジェクトの管理を行う必要があります。
どうすればよいでしょうか?
- A. 運用エンジニアに Google Cloud Shell を利用するためのアクセス権を付与します。
- B. 開発チームに運用チームが特定のリモート プロシージャ コール(RPC)を実行してタスクを達成できるようにするAPI サービスを構築させます。
- C. 運用エンジニアがタスクを実行する必要がある場合にクラウド VM への一時的なSSH アクセスを許可する新しいアクセス要求プロセスを開発します。
- D. クラウド VM へのSSH アクセスを許可するために、GCP へのVPN 接続を設定します。
Correct Answer: A
Question 30
この問題については、Dress4Win のケーススタディを参照してください。
Dress4Win 社は既存の利用パターンを反映したデータやトラフィックの増加に伴い、1年後には 10倍の規模に成長すると予想しています。
CIOは今後 6ヶ月以内に本番環境をクラウドに移行することを目標に掲げています。
アプリケーションに大きな変更を加えることなく、この成長に合わせて拡張し、ROI を最大化するためにどのようにソリューションを構成するのでしょうか?
- A.
- Tomcat とNginx にマネージド インスタンス グループ を実装します。
- MySQL を Google Cloud SQL に、RabbitMQ を Google Cloud Pub/Sub に、Hadoop を Google Cloud Dataproc に、NAS を Google Cloud Storage に移行します。
- B.
- Tomcat とNginx にマネージド インスタンス グループ を実装します。
- MySQLを Google Cloud SQL に、RabbitMQ を Google Cloud Pub/Sub に、Hadoopを Google Cloud Dataproc に、NAS を Google Compute Engine with Persistent Disk ストレージ に移行します。
- C.
- RabbitMQ を Google Cloud Pub/Sub に、Hadoop を Google BigQuery に、NAS を Google Compute Engine with Persistent Disk ストレージ に移行します。
- Tomcat をデプロイし、Google Cloud Deployment Manager を使用してNginxをデプロイします。
- D.
- Web アプリケーション層を Google App Engine に、MySQL を Google Cloud Datastore に、NAS を Google Cloud Storage に移行します。
- RabbitMQ をデプロイし、Google Cloud Deployment Manager を使用してHadoop サーバーをデプロイします。
Correct Answer: A
Question 31
この問題については JencoMart のケーススタディを参照にしてください。
JencoMart 社がユーザー資格情報データベースを Google Cloud Platform に移行し、古いサーバーをシャットダウンしてから数日後、アプリケーションサーバーにデータベースのリクエストを正常に提供されていますが新しいデータベースサーバーがSSH 接続に反応しなくなりました。
この問題を診断するにはどのような 3つのステップを踏むべきでしょうか?(回答を 3つ選択してください)
- A. VM とディスクを削除し、新しいものを作成します。
- B. インスタンスを削除し、ディスクを新しいVM に接続して調査します。
- C. ディスクのスナップショットを取り、新しいマシンに接続して調査します。
- D. マシンが接続しているネットワークのインバウンド ファイアウォールのルールを確認します。
- E. マシンを非常に簡単なファイアウォール ルールで別のネットワークに接続して調査します。
- F. トラブルシューティングのためにインスタンスのシリアルポート出力を印刷し、インタラクティブコンソールを起動し、調査します。
Correct Answer: C、D、F
D: 「ポート22に接続できません」というエラーメッセージの処理考えられる原因は次のとおりです。
ポート上でのSSH アクセスを許可するファイアウォール ルールが存在しない。ポート 22でのSSH アクセスは、デフォルトで全ての Google Compute Engine インスタンスで有効になっています。アクセスを無効にしている場合、ブラウザからのSSH は動作しません。ポート 22以外で sshd を実行する場合は、カスタムのファイアウォール ルールでそのポートへのアクセスを有効にする必要があります。
SSH アクセスを許可するファイアウォール ルールは有効になっていますが、GCP Console サービスからの接続を許可するようには設定されていません。ブラウザベースのSSH セッションの送信元IP アドレスは、GCP Console によって動的に割り当てられ、セッションごとに異なる場合があります。
Reference contents:
– SSH のトラブルシューティング
– ブラウザからの SSH
Question 32
会社の検証スイートは Linux 仮想マシン上で毎日テストを実行するカスタム C++ アプリケーションです。
検証用に予約された限られた数の構内サーバー上で実行されるため、完全な検証スイートを完成させるのに数時間かかります。会社ではシステムの変更を完全にテストするのにかかる時間を短縮し、テストの変更をできるだけ少なくするために、検証インフラストラクチャをクラウドに移行したいと考えています。
どのクラウド インフラストラクチャをお勧めしますか?
- A. Google Compute Engine の非マネージド インスタンス グループとNetwork Load Balancer です。
- B. Google Compute Engine のマネージド インスタンス グループとオートスケーリング です。
- C. Google Cloud Dataproc でApache Hadoop ジョブを実行して各テストを処理します。
- D. Google App Engine と Google Stackdriver でロギングを行います。
Correct Answer: B
Google Compute Engine はユーザーがオンデマンドでVM を起動できるようにします。VM は、標準イメージまたはユーザーが作成したカスタムイメージから起動することができます。
マネージド インスタンス グループにはオートスケーリング機能があり、負荷の増減に応じてマネージド インスタンス グループから自動的にインスタンスを追加または削除することができます。オートスケーリングはアプリケーションがトラフィックの増加に優雅に対応し、リソースの必要性が低い場合にコストを削減するのに役立ちます。
Reference contents:
– インスタンス グループ
Question 33
顧客は既存の企業アプリケーションをオンプレミスのデータセンターから Google Cloud Platform に移行しています。
ビジネスオーナーはユーザーの混乱を最小限に抑える、パスワードを保存するためのセキュリティチームの厳格な要件にする必要があります。
どのような認証戦略を使用するべきでしょうか?
- A. G Suite Password Sync を使用してパスワードを Google に複製します。
- B. SAML 2.0 を介して既存の ID プロバイダに認証を渡します。
- C. Google Cloud Directory Sync ツールを使用して Google でユーザーをプロビジョニングします。
- D. ユーザーに企業のパスワードと一致するように Google のパスワードを設定するように依頼します。
Correct Answer: B
Reference contents:
– ハイブリッド環境で企業ユーザーを認証する
Question 34
チームの開発者の 1人が次の Dockerfile を使って Google Container Engine にアプリケーションをデプロイしましたが、アプリケーションのデプロイに時間がかかりすぎると報告しています。
FROM ./src
RUN apt-get update && apt-get install -y python python-pip
RUN pip install -r requirements.txtどうすればいいでしょうか?(回答を 2つ選びなさい)
- A. pip を実行した後に Python を削除します。
- B. requirements.txt から依存関係を削除する。
- C. Alpine linux のようなスリムダウンされたベースイメージを使用する。
- D. Google Container Engine ノードプールには、より大きなマシンタイプを使用します。
- E. パッケージの依存関係(Python とpip)がインストールされた後にソースをコピーします。
Correct Answer: C、E
アップロードしたアプリのサイズを制限したり、Dockerfile が存在する場合は必要なビルドの複雑さを制限したり、高速で信頼性の高いインターネット接続を確保したりすることで、デプロイのスピードを変えることができます。
注意: Alpine Linuxは、musl libc とbusybox を中心に構築されています。これにより、従来のGNU/Linux ディストリビューションよりも小さく、リソース効率が高くなっています。コンテナに必要な容量は 8MB以下で、ディスクへの最小限のインストールで約 130MBのストレージを必要とします。本格的な Linux 環境を手に入れることができるだけでなく、リポジトリーから多くのパッケージを選択することができます。
Reference contents:
– Google App Engine is slow to deploy, hangs on “Updating service [someproject]…”
– Small. Simple. Secure.
Question 35
この問題については Dress4Win のケーススタディを参照してください。
Dress4Win 社はレガシーサービスのいくつかについて Google Stackdriverを使用して新しいアップタイム チェックを設定しましたが Stackdriver のダッシュボードでは、サービスが健全であることが報告されていません。
どうすればいいのでしょうか?
- A. GoogleStackdriverMonitoring-UptimeChecks の値が一致する場合、ユーザーエージェントの HTTP ヘッダを含むリクエストを許可するように、レガシー Web サーバーを設定します。
- B. GCP コンソールでアップタイム サーバーのIP アドレスのリストをダウンロードし、インバウンド ファイアウォール ルールを作成します。
- C. レガシー Web サーバーのすべてに Stackdriver エージェントをインストールします。
- D. 値が GoogleStackdriverMonitoring-UptimeChecks に一致した場合に User-Agent HTTP ヘッダを通過させるようにロードバランサーを設定します。
Correct Answer: B
Question 36
会社は開発者により良い体験を提供するためにAPI の大規模な改訂を行うことを決定しました。
新しい顧客やテスターが新しいAPI をテストができるようにしながら、古いバージョンのAPI を利用可能でデプロイ可能な状態にしておく必要があります。両方のAPI を提供するために、同じSSL とDNS レコードを維持したいと考えています。
どうすればいいのでしょうか?
- A.新しいバージョンのAPI 用に新しいロードバランサーを構成します。
- B.新しいAPI に新しいエンドポイントを使用するように古いクライアントを再構成します。
- C.パスに基づいて古いAPI がトラフィックを新しいAPIに転送するようにします。
- D.ロードバランサーの背後にあるAPI パスごとに個別のバックエンドプールを使用します。
Correct Answer: D
Reference contents:
– API ライフサイクル管理
Question 37
開発チームから Kubernetes のデプロイファイルが提供されました。
まだインフラストラクチャがないため、アプリケーションをデプロイする必要があります。
何をすべきでしょうか?
- A. gcloud を使用して Kubernetes クラスタを作成し、Google Cloud Deployment Manager を使用してデプロイメントを作成します。
- B. gcloud を使用して Kubernetes クラスタを作成し、kubect1 を使用して配置を作成します。
- C. kubect1 を使用して Kubernetes クラスタを作成し、Google Cloud Deployment Manager を使用してデプロイメントを作成します。
- D. kubect1 を使用して Kubernetes クラスタを作成し、kubect1 を使用して配置を作成します。
Correct Answer: B
Reference contents:
– 単一ゾーンクラスタの作成
Question 38
1日のトラフィックが多い時間帯に、リレーショナル データベースの1つがクラッシュしますが、レプリカがマスターにプロモートされることはありません。 将来的にはこれを避けたいと思います。
何をするべきか?
- A. 別のデータベースを使用してください。
- B. データベースに大きなインスタンスを選択します。
- C. データベースのスナップショットをより定期的に作成します。
- D. データベースの定期的にスケジュールされたフェイルオーバーを実装します。
Correct Answer: D
Reference contents:
– 障害復旧計画ガイド
Question 39
アップロードされた画像から有名な絵画を認識するアプリケーションを Google Cloud ML Engine を使って開発しました。
アプリケーションをテストして特定の人に次の 24時間の間は画像のアップロードを許可したいと考えていますがすべてのユーザーが Google アカウントを持っているわけではありません。
どのようにユーザーに画像をアップロードさせるべきでしょうか?
- A. ユーザーに Google Cloud Storage に画像をアップロードさせ、24時間後に有効期限が切れるパスワードでバケットを保護します。
- B. 24時間後に有効期限が切れる署名付きURL を使用して、ユーザーに画像をGoogle Cloud Storage にアップロードさせます。
- C. ユーザーが画像をアップロードできる Google App Engine でWeb アプリケーションを作成し、24時間後にアプリケーションを無効にするようにGoogle App Engine を設定します。Google Cloud Identity を使用してユーザーを認証します。
- D. ユーザーが画像をアップロードできる Google App Engine でWeb アプリケーションを作成し、Google Cloud Identity を介してユーザーを認証します。
Correct Answer: A
Reference contents:
– 署名付き URL を活用して Cloud Storage に画像ファイルを直接アップロードするアーキテクチャを設計する
Question 40
顧客のユーザーは最近更新された Google App Engine アプリケーションの一部のユーザーがロードに約 30 秒かかるという報告を受けていますが、この動作はアップデート前には報告されていませんでした。
どのような戦略を取るべきでしょうか?
- A. 利用しているISP と協力して問題を診断します。
- B. サポートチケットを開き、問題を診断するためにネットワークキャプチャとフローデータを要求し、アプリケーションをロールバックします。
- C. 最初は以前の既知の良いリリースにロールバックし、その後 Stackdriver Trace とLogging を使用して開発/テスト/ステージング環境で問題を診断します。
- D. 以前の既知の良好なリリースにロールバックし、その後、より静かな時期に再度リリースをプッシュして調査します。その後、Stackdriver Trace とLogging を使用して問題を診断します。
Correct Answer: C
SStackdriver Logging では Google Cloud Platform やAmazon Web Services(AWS)からのログデータやイベントの保存、検索、分析、監視、アラートを行うことができます。また、GCP のAPI は、任意のソースから任意のカスタムログデータをインジェストすることも可能です。Stackdriver Logging はフルマネージド サービスで規模に応じて実行され、何千ものVM からアプリケーションやシステムのログデータを調査することができます。さらに優れているのは、すべてのログデータをリアルタイムで分析することができることです。
Reference contents:
– Cloud Logging
Question 41
あるアプリケーション開発チームは現在使用しているロギングツールでは新しいクラウドベースの製品に対するニーズを満たすことができないと考えています。
チームはエラーをキャプチャし、過去のログデータを分析するのに役立つデベロッパーツールを求めています。
チームからのニーズを満たすソリューションを見つけるサポートするにはどうすればよいでしょうか?
- A. Google StackDriver Logging エージェントをダウンロードしてインストールするように指示します。
- B. Logging のベスト プラクティスに関するオンライン リソースのリストを送信します。
- C. 要件を定義し、実行可能なロギング ツールを評価するのをサポートします。
- D. 新しい機能を利用するために、現在のツールをアップグレードするのをサポートします。
Correct Answer: C
要件を定義し、実行可能なロギングツールを評価するのを支援します。チームは要件と既存のツールの問題点を知っています。StackDriver Logging と Error Reporting がチームの要件をすべて満たしている可能性があるのは事実ですが、他にも彼らのニーズを満たすツールがあるかもしれません。新しいツール、具体的には「エラーをキャプチャし、過去のログデータを分析するのに役立つ」ロギングツールの評価を行うための専門知識を提供する必要があります。
Reference contents:
– 単一の VM に Cloud Logging エージェントをインストールする
Question 42
会社のユーザーフィード バックポータルは 2つのゾーンにレプリケートされた標準のLAMP スタックで構成されています。
これは us-central1 リージョンに配置され、データベースを除くすべてのレイヤーでオートスケールのマネージドインスタンスグループを使用しています。現在、ポータルにアクセスできるのは一部の顧客のみです。ポータルは、この条件では 99.99%の可用性 SLA を満たしていますが、次の四半期には認証されていないユーザーを含むすべてのユーザーがポータルを利用できるようにする予定です。ユーザーの負荷が追加された場合、システムが SLA を維持していることを確認するために、回復力テスト戦略を策定する必要があります。
どうすればよいでしょうか?
- A. 既存のユーザー入力をキャプチャし、すべてのレイヤーでオートスケールがトリガーされるまでキャプチャしたユーザー負荷を再生します。同時にいずれかのゾーンのすべてのリソースを終了させます。
- B. 新しいシステムをより多くのユーザー グループに公開し、すべてのレイヤーでオートスケール ロジックが作動するまで、グループのサイズを毎日増やします。同時に両方のゾーンのランダムなリソースを終了させます。
- C. 合成ランダムユーザ入力を作成し、少なくとも1つのレイヤーでオートスケールロジックがトリガされるまで合成負荷を再生し、両方のゾーンのランダムリソースを終了させることにより、システムに「カオス」を導入します。
- D. 既存のユーザ入力をキャプチャし、リソース利用率が80%を超えるまでキャプチャしたユーザ負荷を再生します。また、既存ユーザーのアプリ利用状況から推定ユーザー数を導き出し、予測負荷の 200%を処理するのに十分なリソースを配備します。
Correct Answer: A
Question 43
災害復旧計画の実施の一環として、会社では Google Cloud VPN 接続を使用して、プライベート データセンターから GCP プロジェクトに本番用 MySQL データベースをレプリケートしようとしています。
遅延の問題と少量のパケットロスが発生し、レプリケーションが中断しています。
どうすればよいでしょうか?
- A. VPN接続を追加し、負荷分散を行います。
- B. Google Cloud Dedicated Interconnect を設定します。
- C. レプリケートされたトランザクションを Google Cloud Pub/Sub に送信します。
- D. UDP を使用するようにレプリケーションを設定します。
- E. Google Cloud SQLを使用して毎日データベースを復元します。
Correct Answer: B
Question 44
バックエンドとして SQL を使用して Google App Engine Standard サービスでPHP をデプロイしています。データベースへのクエリ数を最小限に抑えたいと考えています。
あなたは何をすべきでしょうか?
- A. Memcache サービスレベルを専用に設定します。 クエリのハッシュからキーを作成し、Google Cloud SQL にクエリを発行する前に、Memcache からデータベース値を返します。
- B. Memcache サービスレベルを専用に設定します。 毎分実行される cron タスクを作成して、クエリ結果を含むキーをキャッシュに入力します。
- C. Memcache サービスレベルを共有に設定します。 毎分実行される cron タスクを作成して、予想されるすべてのクエリを「cached-queries」というキーに保存します。
- D. Memcache サービスレベルを共有に設定します。 「cached-queries」というキーを作成し、Google Cloud SQL へのクエリを使用する前に、キーからデータベース値を返します。
Correct Answer: A
Reference contents:
– Memcache の使用
Question 45
会社はエンタープライズ データウェア ハウスとして Google BigQuery を使用しています。
データは複数の Google Cloud プロジェクトに分散されます。Google BigQuery のすべてのクエリは単一のプロジェクトで請求する必要があります。 データを含むプロジェクトでクエリ コストが発生しないようにユーザーはデータセットをクエリできる必要がありますが、編集することはできません。
ユーザーのアクセス ロールをどのように構成する必要がありますか?
- A.
- すべてのユーザーをグループに追加します。
- 課金プロジェクトでは Google BigQuery ユーザーの役割をデータを含むプロジェクトでは Google BigQuery dataViewerの役割をグループに付与します。
- B.
- すべてのユーザーをグループに追加します。
- 課金プロジェクトでの Google BigQuery dataViewerの役割とデータを含むプロジェクトでの Google BigQuery ユーザーの役割をグループに付与します。
- C.
- すべてのユーザーをグループに追加します。
- 課金プロジェクトでは Google BigQuery jobUser の役割をデータを含むプロジェクトでは Google BigQuery dataViewer の役割をグループに付与します。
- D.
- すべてのユーザーをグループに追加します。
- 課金プロジェクトでの Google BigQuery dataViewerの役割とデータを含むプロジェクトでの Google BigQuery jobUserの役割をグループに付与します。
Correct Answer: A
Reference contents:
– インタラクティブ クエリとバッチクエリのジョブの実行
Question 46
この問題については JencoMart のケーススタディを参照にしてください。
JencoMart 社のセキュリティ チームはすべての Google Cloud Platform インフラストラクチャが本番 リソースと開発 リソースの間で管理の職務を分離した最小特権モデルを使用してデプロイされることを要求しています。
どの Google ドメインとプロジェクト構造をお勧めしますか?
- A. ユーザーを管理するために 2 つの G Suite アカウントを作成します。各アカウントにはアプリケーションごとに 1つのプロジェクトが含まれている必要があります。
- B. ユーザーを管理するために 2つの G Suite アカウントを作成します。1つはすべての開発 アプリケーション用の 1つのプロジェクト、もう 1つはすべての本番 アプリケーション用の 1つのプロジェクトです。
- C. 1つの G Suite アカウントを作成して、各アプリケーションの各ステージのユーザーをそれぞれのプロジェクトで管理します。
- D. 1つの G Suite アカウントを作成し、開発/テスト/ステージング環境用の 1つのプロジェクトと本番環境用の 1つのプロジェクトでユーザーを管理します。
Correct Answer: D
注:最小特権の原則と職務分離の原則は、意味的には異なるが、セキュリティの観点からは本質的に関連する概念である。両者の背後にある意図は、人々が実際に必要以上に高い特権レベルを持つことを防ぐことです。
– 最小特権の原則:ユーザーは、ジョブを実行するのに必要な最小限の権限しか持たず、それ以上の権限は持たないようにします。これにより、ターゲット、ジョブ、監視テンプレートなど、権限のないリソースへのアクセスを制限することで、権限の搾取を減らすことができます。
– 職務の分離:ユーザーの特権レベルを制限するだけでなく、ユーザーの職務、つまりユーザーが実行できる特定の仕事も制限します。いかなるユーザーにも、複数の関連する機能の責任を与えてはいけません。これにより、ユーザーが悪意のある行為を行い、その行為を隠蔽する能力が制限されます。
Reference contents:
– 職掌分散
Question 47
この問題については、Dress4Win のケーススタディを参照してください。
ソリューションを移行する前に、オンプレミスのアーキテクチャがビジネス要件を満たしていることを確認したいと思います。
オンプレミスのアーキテクチャではどのような変更を行うべきでしょうか?
- A. RabbitMQ を Google Pub/Subに置き換えます。
- B. MySQL を Google Cloud SQL for MySQLでサポートされている v5.7にダウングレードします。
- C. コンピュートリソースのサイズを、定義済みの Google Compute Engine マシンタイプに合わせて変更します。
- D. マイクロサービスをコンテナ化し、Google Kubernetes Engine でホストします。
Correct Answer: C
Question 48
ソリューションではステージング 環境やテスト 環境では確認できなかったパフォーマンスバグが本番 環境で発生しています。
将来的にこの問題が発生しないように、テストとデプロイの手順を調整したいと考えています。
どうすればよいでしょうか?
- A. より小さな変更を本番に展開します。
- B. テスト 環境とステージング 環境の負荷を増やします。
- C. 本番 環境に展開する前に、一部のユーザーに変更を展開します。
- D. 本番 環境への変更の導入数を減らします。
Correct Answer: B
Question 49
会社はユーザーが会社のWeb サイトからダウンロードできるレンダリング ソフトウェアを作成しています。
世界中に顧客がおり、すべての顧客のためにレイテンシを最小限に抑え、Google のベスト プラクティスに従いたいと考えています。
ファイルはどのように保存しますか?
- A. Google Cloud Multi-Regional Storage バケットに保存します。
- B. ファイルを Google Cloud Regional Storage バケットに保存します。
- C. Google Cloud Multi-Regional Storage バケットにファイルを保存し、地域のゾーンごとに 1つのバケットに保存します。
- D. Google Cloud Multi-Regional Storage バケット、マルチ リージョンごとに 1つのバケットにファイルを保存します。
Correct Answer: A
Reference contents:
– バケットのロケーション>マルチリージョン
Question 50
組織では法的手続きの可能性のある将来の分析のために、すべてのアプリケーションのメトリックを 5年間保持する必要があります。
どのアプローチを使用すべきでしょうか?
- A. セキュリティ チームに各プロジェクトのログへのアクセス権を付与します。
- B. すべてのプロジェクトに対して Stackdriver Monitoring を構成し、Google BigQuery にエクスポートします。
- C. デフォルトの保持ポリシーを使用して、すべてのプロジェクトに対して Stackdriver Monitoring を構成します。
- D. すべてのプロジェクトに対して Stackdriver Monitoring を構成し、Google Cloud Stotage にエクスポートします。
Correct Answer: D
Reference contents:
– ストレージ クラス
– ログのエクスポートの概要
– 割り当てと上限
– Google BigQurey > 料金
Question 51
モバイル チャット アプリケーションを設計しています。
特定のユーザーが送信したメッセージを提供することでチャット メッセージのなりすましができないようにしたいと考えています。
何をすべきですか?
- A. メッセージのクライアント側に発信元のユーザ IDと送信先のユーザをタグ付けします。
- B. 公開鍵基盤(PKI)を用いて、発信元ユーザの秘密鍵を用いてメッセージのクライアント側を暗号化します。
- C. メッセージ クライアント側を共有鍵を用いたブロックベースの暗号化で暗号化します。
- D. クライアント アプリケーションとサーバ間のSSL 接続を有効にするために、信頼できる証明書局を使用します。
Correct Answer: B
Question 52
組織では3 層のWeb アプリケーションが Google Cloud Platform 上の同じネットワークに展開されています。
各層(Web、API、データベース)は他の層とは独立してスケーリングします。ネットワーク トラフィックはWeb を通ってAPI 層に流れ、その後データベース層に流れる必要がありますが、トラフィックはWeb 層とデータベース層の間を間を流れてはなりません。
ネットワークはどのように構成するべきですか?
- A.各層を異なるサブネットワークに追加します。
- B.個々のVM にソフトウェアベースのファイアウォールを設定します。
- C.各層にタグを追加し、目的のトラフィック フローを可能にするルートを設定します。
- D.各層にタグを追加し、ファイアウォール ルールを設定して目的のトラフィック フローを許可します。
Correct Answer: D
Google Cloud Platform は、ルールとタグを介してファイアウォール ルールを適用します。Google Cloud Platform のルールとタグは一度定義すれば、すべての地域で使用できます。
Reference contents:
– OpenStack ユーザーのための Google Cloud
– Building three-tier architectures with security groups
Question 53
この問題については Mountkirk Games のケーススタディを参照してください。
Mountkirk Games 社は分離されたアプリケーション環境を展開するための反復可能で構成可能なメカニズムを作成する必要があります。
開発者とテスターはお互いの環境とリソースにアクセスできますが、ステージング リソースや本番 リソースにはアクセスできません。ステージング 環境では本番 環境から一部のサービスにアクセスする必要があります。
開発 環境をステージングと本番 環境から分離するにはどうすればよいですか?
- A.開発とテスト用のプロジェクトと、ステージングと本番 用のプロジェクトを作成します。
- B.開発用に1つのサブネットワークを作成し、ステージングと本番用に別のサブネットワークを作成します。
- C.開発用に 1つ、ステージング用に 2つ、本番用に 3つ目のプロジェクトを作成します。
- D.開発とテスト用のネットワークと、ステージングと本番用のネットワークを作成します。
Correct Answer: C
Question 54
この問題については TerramEarth のケーススタディを参照してください。
技術的な要件を考慮すると GCP で計画外の車両のダウンタイムをどのように削減するべきでしょうか?
- A. データウェア ハウスとして Google Cloud Dataproc Hive を使用します。パーティショニングされたHive のテーブルにデータを直接ストリームする。Pig スクリプトを使ってデータを分析します。
- B. データウェア ハウスとして Google BigQuery を使用します。すべての車両をネットワークに接続し、gcloud を使用して Google Cloud Multi-Regional Storage バケットにgzip ファイルをアップロードします。分析とレポート作成に Google Data Studio を使用します。
- C. データウェア ハウスとして Google BigQuery を使用します。すべての車両をネットワークに接続し、Google Cloud Pub/Sub と Google Cloud Dataflow を使用して Google BigQuery にデータをストリームします。分析とレポート作成に Google Data Studio を使用します。
- D. データウェア ハウスとして Google Cloud Dataproc Hive を使用します。Google Cloud Multi-Regional Storage バケットにgzip ファイルをアップロードします。このデータを gcloud を使用して Google BigQuery にアップロードします。分析とレポート作成に Google Data Studio を使用します。
Correct Answer: C
Question 55
この問題については Mountkirk Games のケーススタディを参照してください。
Mountkirk Games 社はクラウドとテクノロジーの改善が利用可能になったときに活用できるように将来に向けたソリューションを設計したいと考えています。
どのステップを踏むべきでしょうか?(回答を 2つ選択してください)
- A. 将来のユーザーの行動を予測するための機械学習モデルのトレーニングに使用できるように、現在経済的に実現可能な限り多くの分析データとゲームアクティビティデータを保存します。
- B. ゲーム バックエンド アーティファクトをコンテナイメージにパッケージ化し、Google Kubernetes Engine で実行してゲームアクティビティに基づいてスケールアップまたはスケールダウンするための可用性を向上させます。
- C. Jenkins とSpinnaker を使用して CI/CD パイプラインをセットアップし、カナリアの展開を自動化し、開発速度を向上させます。
- D. データベースに追加のプレーヤーデータを保存する必要がある新しいゲーム機能を追加するときのダウンタイムを減らすために、スキーマバージョン管理ツールを採用します。
- E. Linux VM に毎週のローリング メンテナンス プロセスを実装して、重要なカーネルパッチとパッケージの更新を適用し、ゼロデイ脆弱性のリスクを軽減できるようにします。
Correct Answer: B、C
Question 56
アプリケーションはクレジットカード取引を処理する必要があります。
取引データと使用されている支払い方法に関連する傾向を分析する機能を損なうことなく、PCI(Payment Card Industry)コンプライアンスの最小範囲が必要です。
アーキテクチャをどのように設計する必要がありますか?
- A. トークン化サービスを作成し、トークン化されたデータのみを保存します。
- B. クレジットカード データのみを処理する個別のプロジェクトを作成します。
- C. 個別のサブネットワークを作成し、クレジットカード データを処理するコンポーネントを分離します。
- D. PCI データを処理するすべてのVM にラベルを付けることにより、監査検出フェーズを合理化します。
- E. Google BigQuery へのログ エクスポートを有効にし、ACL とビューを使用して監査人と共有されるデータのスコープを設定します。
Correct Answer: A
Reference contents:
– PCI データ セキュリティ基準の遵守
Question 57
新しいGCP プロジェクトに対するチームの準備状況を評価する必要があります。
評価を実行し、コスト最適化のビジネス目標を組み込んだスキル ギャップ計画を作成する必要があります。 チームはこれまでに 2つの GCP プロジェクトを正常にデプロイしました。
何をするべきでしょうか?
- A.チーム トレーニングに予算を割り当て、新しい GCP プロジェクトの期限を設定します。
- B.チーム トレーニングに予算を割り当て、 チームが職務に基づいてGoogleCloud 認定を取得するためのロードマップを作成します。
- C.熟練した外部コンサルタントを雇うための予算を割り当て、 新しい GCP プロジェクトの期限を設定します。
- D.熟練した外部コンサルタントを雇うための予算を割り当て、 チームが職務に基づいて Google Cloud 認定を取得するためのロードマップを作成します。
Correct Answer: B
Reference contents:
– Building a Cloud Center of Excellence (PDF)
Question 58
レガシー ストリーミング バックエンド データ API 用にグローバルにスケーリングされたフロントエンドを開発しています。
このAPI は適切な処理のために繰り返しデータがなく、厳密な時系列のイベントを想定しています。
データの 1回限りのFIFO(先入れ先出し)配信を保証するには、どの製品を導入する必要がありますか?
- A. Google Cloud Pub/Sub
- B. Google Cloud Pub/Sub に Google Cloud DataFlow
- C. Google Cloud Pub/Sub に Stackdriver
- D. Google Cloud Pub/Sub に Google Cloud SQL
Correct Answer: B
Reference contents:
– メッセージの順序指定
Question 59
この問題については Mountkirk Games のケーススタディを参照してください。
MountkirkGames 社のゲームサーバーは自動的に適切にスケーリングされていません。
先月、MountkirkGamesは新機能を公開しましたが、突然非常に人気がありました。 記録的な数のユーザーがサービスを使用しようとしていますが、多くのユーザーが 503 エラーを受け取り、応答時間が非常に遅くなっています。
最初に何を調査する必要がありますか?
- A.データベースがオンラインであることを確認してください。
- B.プロジェクトの割り当てを超えていないことを確認します。
- C.新しい機能コードでパフォーマンスのバグが発生していないことを確認します。
- D.負荷テストチームが本番 環境に対してツールを実行していないことを確認します。
Correct Answer: B
503 はサービス利用不可エラーです。 データベースがオンラインの場合、誰もが 503 エラーを受け取ります。
Reference contents:
– 割り当ての操作 > 使用量の上限を設定する
Question 60
Google Cloud CDN を使用して、Google Compute Engine インスタンス グループでホストされている静的 HTTP (S) Web サイトコンテンツを配信していますがキャッシュヒット率を向上させたいと考えています。
何をするべきか?
- A.キャッシュキーをカスタマイズして、キーからプロトコルを省略します。
- B.キャッシュされたオブジェクトの有効期限を短くします。
- C. HTTP (S) ヘッダー「Cache-Region」がユーザーの最も近いリージョンを指していることを確認します。
- D.静的コンテンツをGoogle Cloud Storage バケットに複製し、 Google Cloud CDN をそのバケットのロードバランサーに向けます。
Correct Answer: A
Question 61
リード エンジニアはレガシー データセンターにVMを導入するカスタムツールを作成しました。
カスタムツールを新しいクラウド環境に移行しGoogle Cloud Deployment Manager を採用したいと考えています。
Google Cloud Deployment Manager に移行することの 2つのビジネスリスクは何ですか? (回答を 2つ選択してください)
- A. Google Cloud DeploymentManager はPython を使用しています。
- B. Google Cloud Deployment Manager API は将来廃止される可能性があります。
- C. Google Cloud Deployment Manager は会社のエンジニアにはなじみがありません。
- D. Google Cloud Deployment Manager を実行するには Google API サービス アカウントが必要です。
- E. Google Cloud Deployment Manager を使用して、クラウド リソースを完全に削除できます。
- F. Google Cloud Deployment Manager は Google Cloud リソースの自動化のみをサポートします。
Correct Answer: C、F
Reference contents:
– デプロイの削除
Comments are closed