![[GCP] Google Cloud Certified:Professional Cloud Architect](https://www.cloudsmog.net/wp-content/uploads/google-cloud-certified_professional-cloud-architect-1200x675.jpg)
※ 他の問題集は「タグ:Professional Cloud Architect の模擬問題集」から一覧いただけます。
本模擬問題集は「Professional Cloud Architect Practice Exam (2020.02.07)」を日本語翻訳した模擬問題集です。
Google Cloud 認定資格 – Professional Cloud Architect 模擬問題集(全100問)
QUESTION 1
この質問については、JencoMart のケーススタディを参照してください。
JencoMart のセキュリティチームは、すべてのGoogle Cloud Platform インフラストラクチャが運用リソースと開発リソースの分離した最小限の権限モデルを使ってデプロイされていることを望んでいます。
どのGoogle ドメインとプロジェクト構造をするべきでしょうか?
- A. ユーザーを管理するために開発/テスト/ステージング用と本番用の2つのG Suiteアカウントを作成します。各アカウントにはアプリケーションごとに1つのプロジェクトを含める必要があります。
- B. ユーザーを管理するために2つのG Suiteアカウントを作成します。1つはすべての開発アプリケーション用の単一プロジェクト、もう1つはすべての本番アプリケーション用の単一プロジェクトです。
- C. 1つのG Suiteアカウントを作成して、独自のプロジェクトの各アプリケーションの各段階でユーザーを管理します。
- D. 単一のG Suiteアカウントを作成して、開発/テスト/ステージング環境用の1つのプロジェクトと本番環境用の1つのプロジェクトでユーザーを管理します。
Correct Answer: D
Explanation:
最小限の権限と職務分離の原則は意味的には異なりますが、セキュリティの観点から本質的に関連する概念です。両方の背後にある意図は、人々が実際に必要とするよりも高い特権レベルを持つことを防ぐことです。
- 最小権限の原則:ユーザーは、ジョブの実行に必要な最小限の権限のみを保持し、それ以上は保持しないでください。これにより、認可されていないターゲット、ジョブ、監視テンプレートなどのリソースへのアクセスが制限され、認可の活用が減少します。
- 職務の分離:ユーザー権限レベルを制限するだけでなく、ユーザーの職務、またはユーザーが実行できる特定のジョブも制限します。ユーザーには、複数の関連機能に対する責任を与えないでください。これにより、ユーザーが悪意のある操作を実行し、その操作を隠蔽する能力が制限されます。
Reference:
– 職掌分散
QUESTION 2
この質問については、JencoMart のケーススタディを参照してください。
JencoMart がユーザ認証情報データベースをGoogle Cloud Platform に移行して古いサーバをシャットダウンした数日後、新しいデータベースサーバはSSH 接続に応答しなくなりました。アプリケーション サーバーへのデータベース要求は正しく処理しています。
問題を診断するには、次のどの手順を実行する必要がありますか?(回答は3つ)
- A. 仮想マシン(VM)とディスクを削除して、新しいVMを作成します。
- B. インスタンスを削除し、ディスクを新しいVMに接続して調査します。
- C. ディスクのスナップショットを取得し、新しいマシンに接続して調査します。
- D. マシンが接続されているネットワークの受信ファイア ウォールルールを確認します。
- E. 非常に単純なファイアウォールルールを使用してVMを別のネットワークに接続し、調査します。
- F. トラブルシューティング用にインスタンスのシリアルコンソール出力を印刷し、インタラクティブコンソールをアクティブにして調査します。
Correct Answer: C, D, F
Explanation:
D:Handling「ポート22に接続できません」エラーメッセージは考えられる原因は次のとおりです。
- ポートでSSH アクセスを許可するファイアウォール規則はありません。ポート22でのSSHアクセスは、すべてのGoogle Compute Engine インスタンスでデフォルトで有効になっています。アクセスを無効にした場合、ブラウザからのSSHは機能しません。22以外のポートでsshdを実行する場合は、カスタムファイアウォール規則でそのポートへのアクセスを有効にする必要があります。
- SSH アクセスを許可するファイアウォール規則は有効になっていますが、GCP コンソールサービスからの接続を許可するように設定されていません。ブラウザーベースのSSHセッションのソースIPアドレスは、GCP コンソールによって動的に割り当てられ、セッションごとに異なる場合があります。
F:「接続できませんでした。再試行しています…」エラーの処理
シリアルコンソールの出力ページに移動して、accounts-from-metadata で始まる出力行を探すことで、デーモンが実行されていることを確認できます。
string:標準イメージを使用しているが、シリアルコンソール出力にこれらの出力プレフィックスが表示されない場合は、デーモンが停止している可能性があります。 インスタンスを再起動して、デーモンを再起動します。
Reference:
– ブラウザからの SSH
QUESTION 3
この質問については、JencoMart のケーススタディを参照してください。JencoMartは、ユーザー プロファイル ストレージをGoogle Cloud Datastore に、アプリケーションサーバーをGoogle Compute Engine(GCE)に移行することを決定しました。
移行中に既存のインフラストラクチャはデータをアップロードするためにGoogle Cloud Datastore にアクセスする必要があります。
どのサービス アカウント キーの管理戦略を推奨する必要がありますか?
- A. オンプレミス インフラストラクチャとGCE 仮想マシン(VM)のサービス アカウント キーをプロビジョニングします。
- B. ユーザーアカウントを使用してオンプレミス インフラストラクチャを認証し、VMのサービス アカウント キーをプロビジョニングします。
- C. オンプレミス インフラストラクチャのサービス アカウント キーをプロビジョニングし、VMにGoogle Cloud Platform(GCP)管理鍵を使用します。
- D. GCE / Googleにカスタム認証サービスを展開します。 オンプレミスインフラストラクチャ用のGoogle Kubernetes Engine(GKE)およびVM用のGCP 管理キーを使用します。
Correct Answer: C
Explanation:
Google Cloud Platform へのデータの移行
他のクラウド プロバイダで発生するデータ処理があり、処理したデータをGoogle Cloud Platform に転送するとします。 外部クラウド上の仮想マシンのサービス アカウントを使用して、データをGoogle Cloud Platform にプッシュすることができます。これを行うにはサービス アカウントを作成するときにサービス アカウント キーを作成してダウンロードし、外部プロセスからそのキーを使用してGoogle Cloud Platform API を呼び出す必要があります。
Reference:
– サービス アカウントについて
QUESTION 4
この質問については、JencoMart のケーススタディを参照してください。JencoMartは、アジアへのトラフィックを提供するGoogle Cloud Platform 上にアプリケーションのバージョンを構築しました。
JencoMartのビジネスと技術的な目標に対する成功を測定したいと考えています。
どの指標を追跡する必要がありますか?
- A. アジアからのリクエストのエラー率。
- B. 米国とアジアの待ち時間の違い。
- C. アジアからの総訪問数、エラー率、および待ち時間。
- D. アジアのユーザーの合計訪問数と平均待ち時間。
- E. データベースに存在する文字セットの数。
Correct Answer: D
Explanation:
シナリオから:
ビジネス要件:アジア市場にサービスを展開する。
技術的要件:アジア地区からサービスにアクセスする際のレイテンシを短縮する。
QUESTION 5
この質問については、JencoMart のケーススタディを参照してください。
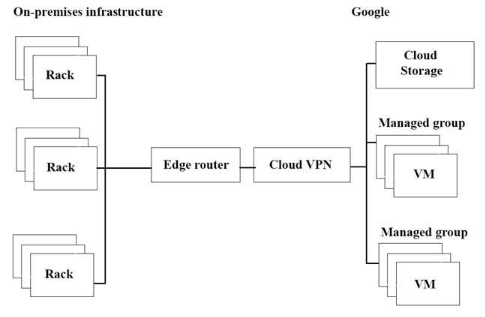
JencoMartのアプリケーションのGoogle Cloud Platform(GCP)への移行の進行が遅れています。インフラストラクチャを上図です。
スループットを最大化したいと望んでいます。
潜在的なボトルネックは何でしょうか?(回答は3つ)
- A. スループットを制限する単一のVPNトンネル。
- B. このタスクに適さないGoogle Cloud Storage の階層。
- C. 長距離での操作に適さないコピーコマンド。
- D. オンプレミス マシンよりもGCPの仮想マシン(VM)が少ない。
- E. VMの外部の独立したストレージレイヤー。このタスクには適していません。
- F. オンプレミス インフラストラクチャとGCP 間の複雑なインターネット接続。
Correct Answer: A、C、E
QUESTION 6
この質問については、JencoMart のケーススタディを参照してください。
JencoMartは、ユーザープロファイル データベースをGoogle Cloud Platformに移動したいと考えています。
どのGoogle データベースを使用する必要がありますか?
- A. Google Cloud Spanner
- B. Google BigQuery
- C. Google Cloud SQL
- D. Google Cloud Datastore
Correct Answer: D
Common workloads:
– ユーザープロファイル
– プロダクトカタログ
– ゲームデータ
Reference:
– クラウド ストレージ プロダクト
– Cloud Datastore の概要
QUESTION 7
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesは、新しいテスト戦略を設計を望んでいます。
テストカバレッジは他のプラットフォームの既存バックエンドとどのように違うべきでしょうか ?
- A. テストは従来のアプローチをはるかに超えて拡張する必要があります。
- B. 単体テストは必要はなく、エンドツーエンドのテストだけが必要です。
- C. リリースが実稼働環境になった後にテストを適用する必要があります。
- D. テストにはGoogle Cloud Platform のインフラストラクチャのを直接テストを含める必要があります。
Correct Answer: A
Explanation:
シナリオから:
Mountkirk Gamesのいくつかのゲームは予想を上回る人気を博したため、世界中のオーディエンス、アプリケーション サーバー、MySQL データベース、分析ツールのスケーリングに関する問題が生じた。
ゲーム分析プラットフォームの要件:ゲーム アクティビティに基づいて動的にスケールアップまたはスケールダウンする
QUESTION 8
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesは、新しいバックエンドをGoogle Cloud Platform(GCP)にデプロイしました。
バックエンドの新しいバージョンが公開される前に、それらのバックエンドの完全なテストプロセスを作成し、テスト環境を経済的な方法で拡張する必要があります。
プロセスをどのように設計するべきでしょか?
- A. 本番環境の負荷をシミュレートするために、GCPでスケーラブルな環境を作成します。
- B.既存のインフラストラクチャを使用して、GCP ベースのバックエンドを大規模にテストします。
- C. GCP内部のリソースを使用してアプリケーションの各コンポーネントにストレステストを構築し、負荷をシミュレートします。
- D. GCP で一連の静的環境を作成し、高/中/低 などのさまざまなレベルの負荷をテストします。
Correct Answer: A
Explanation:
シナリオから:ゲームバックエンドプラットフォームの要件
- ゲーム アクティビティに基づいて動的にスケールアップまたはスケールダウンする。
- マネージド NoSQL データベースと統合する。
- 強化されたLinux ディストリビューション を実行する。
QUESTION 9
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesは、継続的デリバリーパイプラインの確率を望んでいます。
そのアーキテクチャには、迅速に更新およびロールバックできるように考えている小規模サービスが含まれています。
Mountkirk Gamesには次の要件があります。
- サービスは、米国とヨーロッパの複数のリージョンに重複して導入されています。
- フロントエンドサービスのみが公開インターネットで公開されます。
- サービス群に単一のフロントエンド IPを提供できます。
- デプロイメントの成果物は不変です。
どのプロダクトを使用するべきですか?
- A. Google Cloud Storage、Google Cloud Dataflow、Google Compute Engine.
- B. Google Cloud Storage、Google App Engine、Google Network Load Balancer.
- C. Google Kubernetes Registry、Google Container Engine、Google HTTP(S) Load Balancer.
- D. Google Cloud Functions、Google Cloud Pub/Sub、Google Cloud Deployment Manager.
Correct Answer: C
QUESTION 10
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesのゲームサーバーは、自動的に適切にスケーリングされません。
先月、新機能を発表しから非常に人気になりました。記録的なユーザー数がサービスを使用しようとしていますが、多くは503 エラーと受け取り、応答時間が非常に遅くなっています。
最初に何を調査するべきでしょうか?
- A. データベースがオンラインであることを確認します。
- B. プロジェクトの割り当てを超えていないことを確認します。
- C. 新しい機能コードでパフォーマンスのバグが発生しなかったことを確認します。
- D. 負荷テストチームが本番環境に対してツールを実行していないことを確認します。
Correct Answer: B
Explanation:
503 はサービス利用不可エラーです。データベースがオンラインの場合は、すべてのユーザーに503 エラーが表示されます。
QUESTION 11
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesは、分離されたアプリケーション環境を展開するために、再現可能で構成可能なメカニズムを作成する必要があります。
開発者とテスターはお互いの環境とリソースにアクセスできますが、ステージングまたは本番環境のリソースにはアクセスできません。ステージング環境は、本番環境から一部のサービスにアクセスする必要があります。
開発環境をステージングおよび本番環境から分離するにはどうすればよいですか?
- A. 開発とテスト用のプロジェクトと、ステージングと本番用のプロジェクトを作成します。
- B. 開発とテスト用のネットワークと、ステージングと本番用のネットワークを作成します。
- C. 開発用に1つのサブネットワークを作成し、ステージングと本番用に別のサブネットワークを作成します。
- D. 開発用に1つ、ステージング用に2つ目、本番用に3つ目のプロジェクトを作成します。
Correct Answer: D
QUESTION 12
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesは、新しいゲーム用にリアルタイムの分析プラットフォームをセットアップしたいと考えています。
新しいプラットフォームは、技術的要件を満たす必要があります。
すべての要件を満たすGoogle プロダクトの組み合わせはどれです?
- A. Google Kubernetes Engine、Google Cloud Pub/Sub、Google Cloud SQL.
- B. Google Cloud Dataflow、Google Cloud Storage、Google Cloud Pub/Sub、Google BigQuery.
- C. Google Cloud SQL、Google Cloud Storage、Google Cloud Pub/Sub、Google Cloud Dataflow.
- D. Google Cloud Dataproc、Google Cloud Pub/Sub、Google Cloud SQL、Google Cloud Dataflow.
- E. Google Cloud Pub/Sub、Google Compute Engine、Google Cloud Storage、Google Cloud Dataproc.
Correct Answer: B
Explanation:
Google 独自の高速プライベートネットワークを活用したGoogle Cloud Pub/Sub を使用して、世界中のどこからでも毎秒数百万のストリーミングイベントを取り込みます。Google Cloud Dataflow でストリームを処理して、信頼性が高く、一度だけ、低遅延のデータ変換を保証します。変換されたデータをクラウドネイティブのデータウェアハウジングサービスであるGoogle BigQuery にストリーミングして、SQL または一般的な視覚化ツールを使用して即座に分析します。
シナリオから:ゲームのバックエンドをGoogle Compute Engine にデプロイしようと計画しています。これにより、ストリーミング指標の取得や集中的な分析が可能になります。
ゲーム分析プラットフォームの要件:
- ゲーム アクティビティに基づいて動的にスケールアップまたはスケールダウン。
- 着信データをゲームサーバーから迅速に直接処理。
- 低速なモバイル ネットワークが原因で遅延したデータを処理。
- 10 TB 以上の履歴データに対してクエリを実行。
- ユーザーのモバイル デバイスから定期的にアップロードされるファイルを処理。
- 完全に管理されたサービスのみを使用。
Reference:
– ストリーム分析とリアルタイムの分析情報
QUESTION 13
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesは、現在の分析および統計レポートモデルから、Google Cloud Platform 上の技術的要件を満たすモデルに移行したいと考えています。
移行計画に含めるべき2つのステップはどれでしょうか?(回答は2つ)
- A. 現在のバッチ ETL コードをCloud Cloud Dataflow に移行した場合の影響を評価します。
- B. Google BigQuery のパフォーマンスを向上させるために、データを非正規化するスキーマ移行計画を作成します。
- C. 単一のMySQL データベースからMySQL クラスタに移動する方法を示すアーキテクチャ図を作成します。
- D. 前のゲームから10 TBの分析データをGoogle Cloud SQL インスタンスにロードし、データセット全体に対してテストクエリを実行して、正常に完了したことを確認します。
- E. Google Cloud Armor を統合して、Google Cloud Storage にアップロードされた分析ファイル内のSQL インジェクション攻撃の可能性を防ぎます。
Correct Answer: A, B
QUESTION 14
この質問については、Mountkirk Games のケーススタディを参照してください。
会社のMountkirk Gamesのコンピューティングワークロードの技術アーキテクチャを分析および定義する必要があります。
Mountkirk Gamesのビジネス要件と技術的要件を考慮して、何をすべきですか?
- A. ネットワーク ロードバランサを作成します。 Google Compute Engine プリエンプティブル インスタンスを使用します。
- B. ネットワーク ロードバランサを作成します。Google Compute Engine インスタンスを使用します。
- C. マネージド インスタンス グループ(MIG)と自動スケーリングポリシーを使用してネットワーク ロードバランサを作成します。Googel Compute Engine プリエンプティブル インスタンスを使用します。
- D. マネージド インスタンス グループ(MIG)と自動スケーリングポリシーを使用してネットワーク ロードバランサを作成します。 Google Compute Engine インスタンスを使用します。
Correct Answer: D
QUESTION 15
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesは、パブリック クラウドと技術の改善が利用可能になったときにそれを活用するために、将来のためのソリューションを設計したいと考えています。
どのステップを取るべきですか?(回答は2つ)
- A. 将来のユーザー行動を予測するための機械学習モデルを訓練するために利用できるように、現在可能な限り多くの分析データとゲームアクティビティデータを保存します。
- B. ゲームバックエンド アーティファクトをコンテナイメージにパッケージ化し、Google Kubernetes Engine 上で実行することでゲームアクティビティに応じてスケールアップやスケールダウンできる可用性を改善します。
- C. Jenkins とSpinnaker を使って CI/CD パイプラインのセットアップを行い、カナリアの展開を自動化し、開発速度を改善します。
- D. 追加のプレーヤーデータをデータベースに保存する必要がある新しいゲーム機能を追加する際のダウンタイムを短縮するために、スキーマのバージョン管理ツールを採用します。
- E. Linux 仮想マシンに週単位のローリング メンテナンス プロセスを実装して、重要なカーネルパッチとパッケージアップデートを適用し、ゼロデイの脆弱性のリスクを軽減します。
Correct Answer: C, E
QUESTION 16
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Gamesは、モバイルネットワークの遅延の変化に対する分析プラットフォームの復元力をテストする方法を設計したいと考えています。
どうすればいいですか?
- A. ゲーム分析プラットフォームに障害注入ソフトウェアを導入し、モバイルクライアントの分析トラフィックに遅延を追加できます。
- B. Google Compute Engine 仮想マシンの携帯電話エミュレーターから実行できるテストクライアントを構築し、世界中のGoogle Cloud Platform リージョンで複数のコピーを実行して、現実的なトラフィックを生成します。
- C. モバイルデバイスからアップロードされた分析ファイルの処理を開始する前に、ランダムな遅延を導入する機能を追加します。
- D. プレーヤーのモバイルデバイスで実行し、世界中のGoogle Cloud Platform リージョンで実行されている分析エンドポイントから応答時間を収集するゲームのオプトインベータ版を作成します。
Correct Answer: C
QUESTION 17
この質問については、Mountkirk Games のケーススタディを参照してください。
Mountkirk Games のデータベース ワークロードの技術アーキテクチャーを分析および定義する必要があります。
ビジネス要件と技術的要件を考慮してください。
どうすればいいですか?
- A.時系列データにはGoogle Cloud SQL を使用し、履歴データクエリにはGoogle Cloud Bigtable を使用します。
- B. Google Cloud SQL を使用してMySQLを置き換え、Google Cloud Spanner を使用して履歴データクエリを実行します。
- C. Google Cloud Bigtable を使用してMySQLを置き換え、Google BigQuery を履歴データクエリに使用します。
- D.時系列データにGoogle Cloud Bigtable を使用し、トランザクションデータにGoogle Cloud Spanner を使用し、履歴データクエリにGoogle BigQuery を使用します。
Correct Answer: C
QUESTION 18
この質問については、Mountkirk Games のケーススタディを参照してください。
時系列データベースサービスにゲームアクティビティを保存するためのMountkirk の技術的要件を満たすGoogle Cloud ストレージ プロダクトはどれでしょうか?
- A. Google Cloud Bigtable
- B. Google Cloud Spanner
- C. Google BigQuery
- D. Google Cloud Datastore
Correct Answer: A
QUESTION 19
この質問については、Mountkirk Games のケーススタディを参照してください。
新しいゲームバックエンド プラットフォームのアーキテクチャを担当しています。
ゲームはREST API を介してバックエンドと通信します。
Google のベストプラクティスに従います。
バックエンドをどのように設計すべきか?
- A. バックエンドのインスタンス テンプレートを作成します。 すべてのリージョンについて、複数ゾーンのマネージド インスタンス グループ(MIG)にデプロイします。 L4 ロードバランサ(TCP プロキシ負荷分散)を使用します。
- B. バックエンドのインスタンス テンプレートを作成します。 リージョンごとに、単一ゾーンのマネージド インスタンス グループ(MIG)にデプロイします。 L4 ロードバランサ(TCP プロキシ負荷分散)を使用します。
- C. バックエンドのインスタンス テンプレートを作成します。 すべてのリージョンについて、複数ゾーンのマネージド インスタンス グループ(MIG)にデプロイします。L7 ロードバランサ(HTTP(S) 負荷分散)を使用します。
- D. バックエンドのインスタンス テンプレートを作成します。 リージョンごとに、単一ゾーンのマネージド インスタンス グループ(MIG)にデプロイします。 L7 ロードバランサ(HTTP(S) 負荷分散)を使用します。
Correct Answer: A
Reference:
– インスタンス テンプレート
– TCP プロキシ負荷分散のコンセプト
– 【GCP】Cloud Load Balancingによる負荷分散
QUESTION 20
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthのCTOは、接続された車両の生データを使用して、現場の車がいつ壊滅的な故障を起こすかをおおよそ特定したいと考えています。
そのために、ビジネス アナリストが車両データを一元的に照会できるようにする必要があります。
どのアーキテクチャをおすすめしますか?
A.
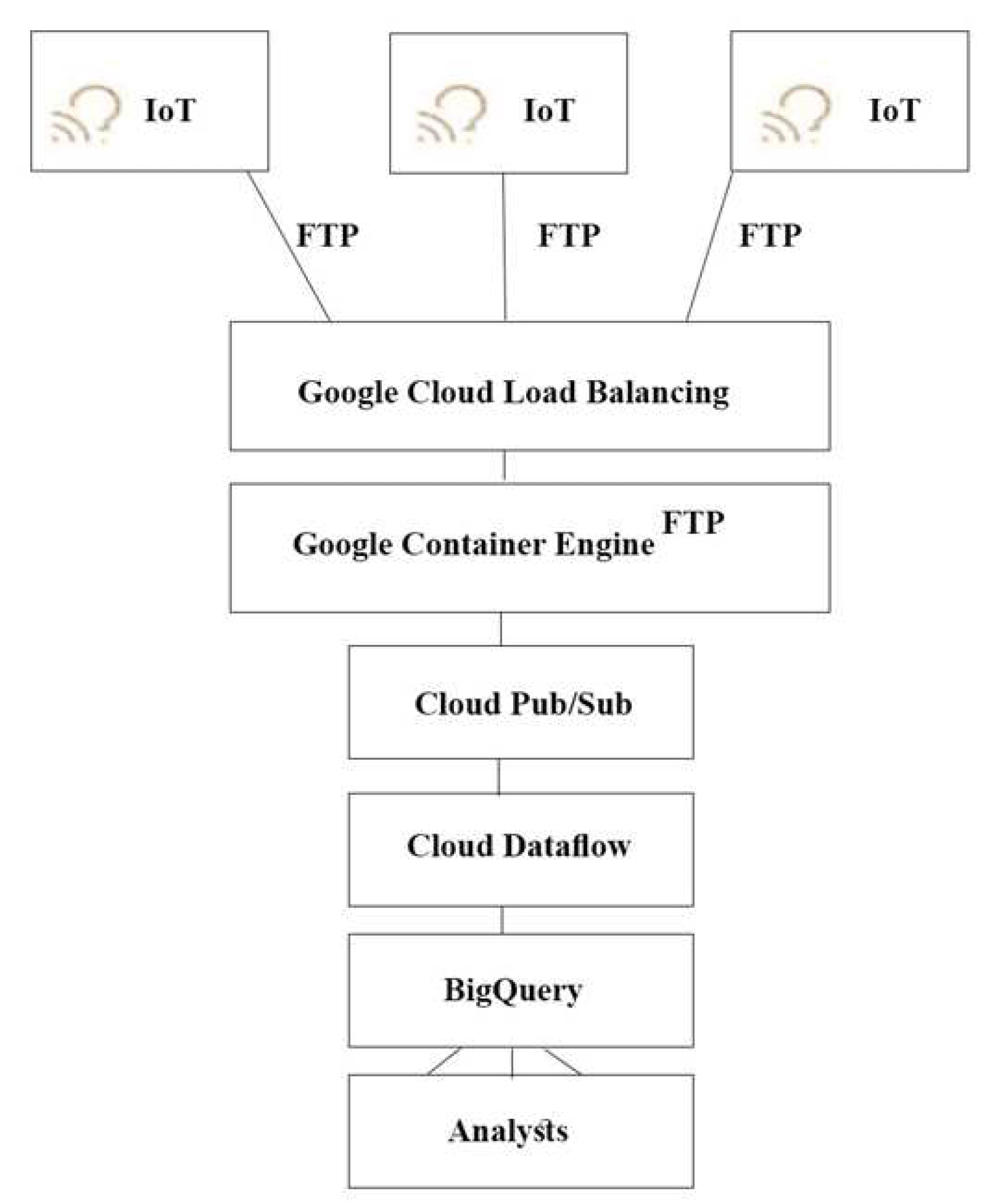
B.
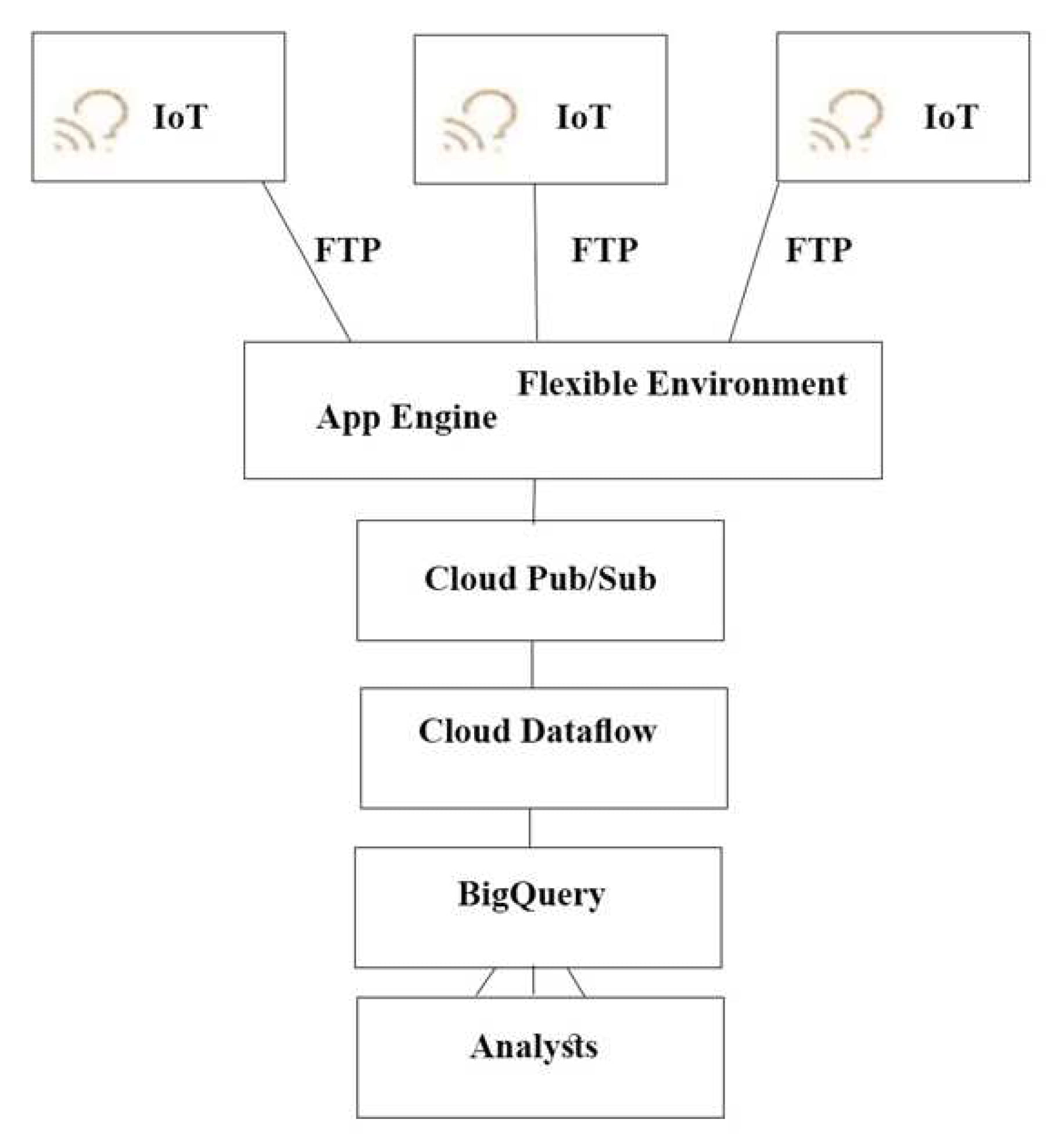
C.
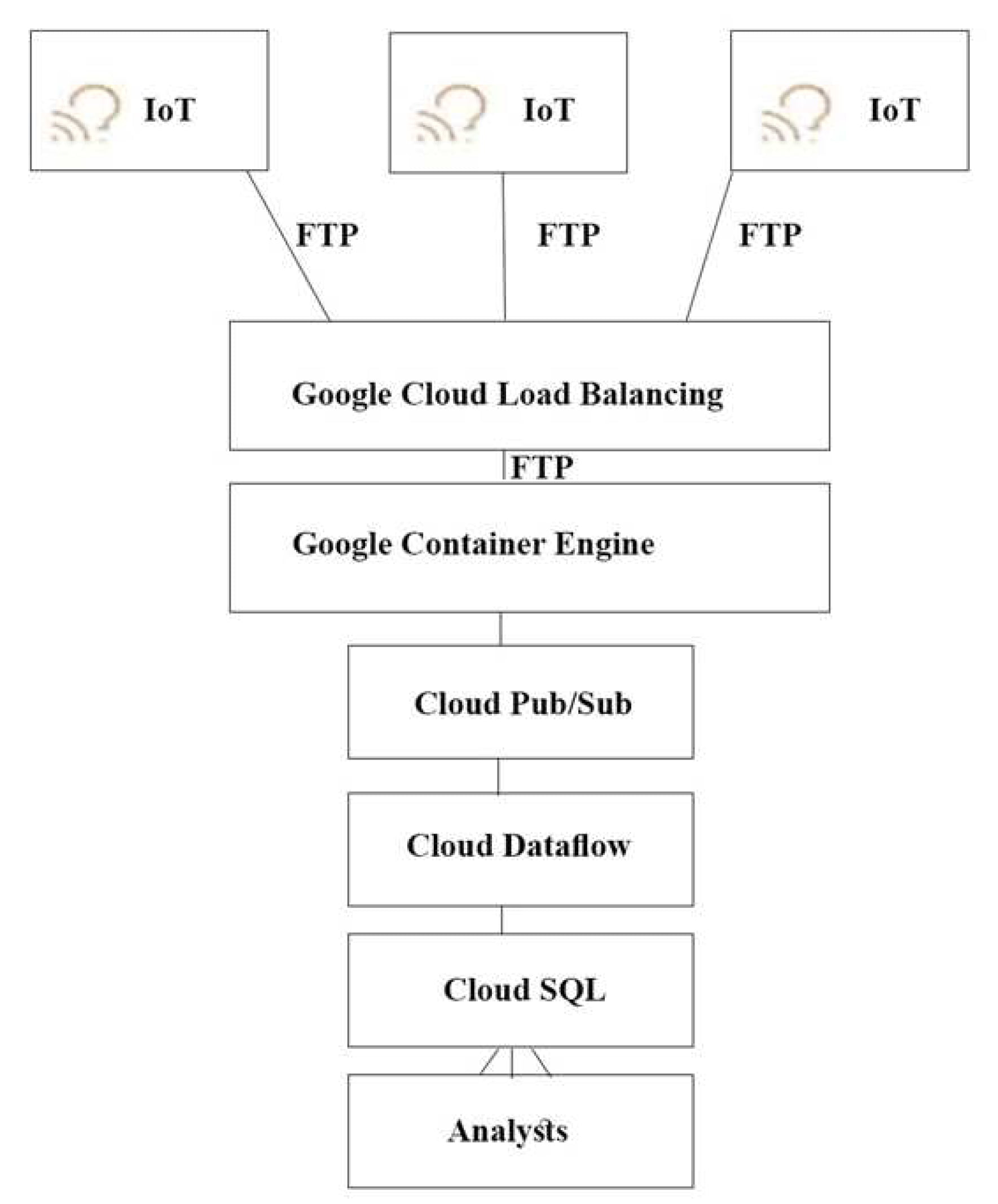
D.
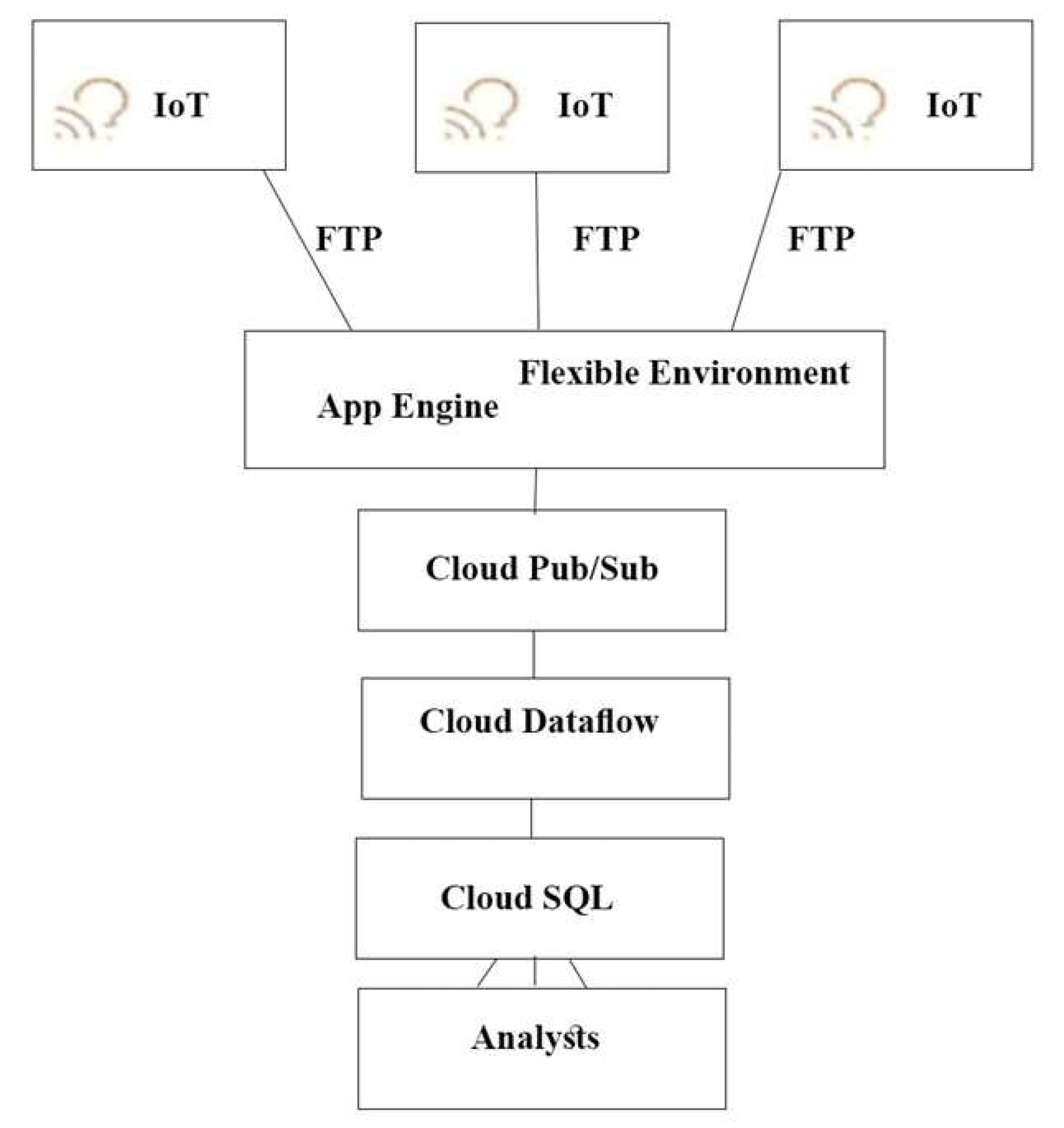
Correct Answer: A
Explanation:
プッシュ エンド ポイントはロードバランサにすることができます。
コンテナ クラスタを使用できます。
Stream Analytics用のGoogle Cloud Pub/Sub。
Reference:
– Google Cloud Pub/Sub
– Google Cloud IoT
– Cloud IoT Core での Connected Vehicle Platform の設計
– データの取り込み (opens in a new tab)”>Cloud IoT Core での Connected Vehicle Platform の設計>データの取り込み
– Google Touts Value of Cloud IoT Core for Analyzing Connected Car Data
QUESTION 21
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthの開発チームは、ビジネス要件を満たすAPIを作成したいと考えています。
開発チームには、カスタム フレームワークを作成するのではなく、ビジネス バリューに開発作業を集中させる必要があります。
どの方法を良いでしょうか?
- A. Google App Engine をGoogle Cloud Endpoints で使用します。ディーラーおよびパートナー向けのAPIに注力します。
- B. JAX-RS Jersey Java ベースのフレームワークでGoogle App Engine を使用します。一般向けのAPIに注力します。
- C. Swagger(Open API 仕様)フレームワークでGoogle App Engineを使用します。一般向けのAPIに注力します。
- D. Django Python コンテナでGoogle Container Engine を使用します。 一般向けのAPIに注力します。
- E. Swagger(Open API 仕様)フレームワークを備えたTomcat コンテナでGoogle Container Engine を使用します。 ディーラーおよびパートナー向けのAPIに注力します。
Correct Answer: A
Explanation:
Google Cloud Endpoints は、APIの開発、デプロイ、保護、監視を行なえます。また、Open API 仕様やGoogle API フレームワークを使って、API 開発のあらゆる段階で必要なツールを提供しています。
シナリオ:ビジネス要件
・車両の計画外停止時間を 1 週間未満に短縮する。
・自社製品の使われ方に関してさらに多くのデータをディーラー網に提供し、新しい製品やサービスをより適切に提案できるようにする。
・急成長を続ける農業ビジネスでの種子供給業者や肥料供給業者を中心にさまざまな企業と提携し、魅力的な製品やサービスを共同で顧客に提供できるようになる。
Reference:
– Google Cloud Endpoints
– App Engine スタンダード環境用 Endpoints スタートガイド
QUESTION 22
この質問については、TerramEarth のケーススタディを参照してください。
開発チームは、車両データを取得するための構造化APIを作成しました。
開発チームは、この車両イベントデータを使用するディーラー用のツールをサードパーティが開発できるようにしたいと考えています。
このデータに対する委任された承認をサポートする必要があります。
どうすればいいでしょうか?
- A. OAuth と互換のあるアクセス制御システムを構築または活用します。
- B. SAML 2.0 SSO 互換性を認証システムに組み込みます。
- C. パートナーシステムのソース IP アドレスに基づいてデータアクセスを制限します。
- D. 信頼できるサードパーティに提供できる各ディーラーの二次認証情報を作成します。
Correct Answer: A
Explanation:
OAuth 2.0 を使用してアプリケーションの承認を委任します。
Google Cloud Platform API は、OAuth 2.0 をサポートしており、スコープはサポートされているメソッドに対してきめ細かな承認を提供します。Google Cloud Platform は、サービス アカウントとユーザーアカウント OAuth(3本足OAuthとも呼ばれる)の両方をサポートしています。
Reference:
– エンタープライズ企業のベスト プラクティス
– 認証の概要
– リクエストの承認
– Using OAuth 2.0 to Access Google APIs
– OAuth 2.0 の設定
QUESTION 23
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthは、現場にある2,000万台すべての車両をパブリック クラウドに接続することを計画しています。
これにより、2,000万600 バイトレコード/秒で40 TB/時のボリューム増加が予想されています。
データの取り込みをどのように設計する必要がありますか?
- A.車両は、Google Cloud Storage にデータを直接書き込みます。
- B.車両は、Google Cloud Pub/Sub にデータを直接書き込みます。。
- C.車両は、データをGoogle BigQuery に直接ストリーミングします。
- D.車両は、引き続き既存のシステム(FTP)を使用してデータを書き込みます。
Correct Answer: C
QUESTION 24
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthのビジネス要件を分析したところ、ダウンタイムを削減し、顧客の部品の待ち時間を短縮することで、時間の大半を節約できることがわかりました。
3週間分の集約レポート時間の短縮に重点を置くことを決定しました。
会社のプロセスにどの変更するべきでしょうか?
- A. CSV形式からバイナリ形式に移行、FTPからSFTP トランスポートに移行を行い、メトリックの機械学習分析を開発します。
- B. FTPからストリーミング トランスポートへの移行、CSVからバイナリ形式への移行して、およびメトリックの機械学習分析を開発します。
- C. フリートのセルラー接続を80%に増やし、FTPからストリーミング トランスポートに移行し、メトリックの機械学習分析を開発します。
- D. FTPからSFTPトランスポートに移行し、メトリックの機械学習分析を開発し、ディーラーのローカル在庫を一定の要因で増やします。
Correct Answer: C
Explanation:
圧縮データをロードする場合は、Avro バイナリ形式をお勧めします。Avro データは、データブロックが圧縮されている場合でもデータを並行して読み取ることができるため、読み込みが高速化できます。
Google Cloud Storage は、HTTP チャンク転送エンコードに基づいて、gsutil ツールまたはboto ライブラリを使用したストリーミング転送をサポートしています。ストリーミングデータを使用すると、データを最初に別のファイルに保存する必要なく、Google Cloud Storageアカウントとの間でデータをストリーミングできます。ストリーミング転送は、データを生成するプロセスがあり、アップロードする前にローカルにバッファリングする必要がない場合やパイプラインからGoogle Cloud Storage に直接結果を送信する場合に便利です。
Reference:
– ストリーミング転送
– データの読み込みの概要
– チャンク転送エンコード
QUESTION 25
この質問については、TerramEarth のケーススタディを参照してください。
Google Cloud Platform の利用を続ける結果、TerramEarthの設備投資(または資産計上)のどれが大きく変化するでしょうか?
- A. 運用コスト/設備投資の割り当て、LANの変更、容量計画。
- B. キャパシティプランニング、TCO計算、運用コスト/設備投資の割り当て。
- C. キャパシティプランニング、使用率測定、データセンターの拡張。
- D. データセンターの拡張、TCO計算、使用率測定。
Correct Answer: B
QUESTION 26
この質問については、TerramEarth のケーススタディを参照してください。
データ取得を高速化するために、より多くの車両がセルラー接続にアップグレードされ、ETLプロセスにデータを送信できるようになります。
現在のFTP プロセスは頻繁にエラーを起こしやすく、接続に失敗するとファイルの初めからデータ転送を再開します。
ソリューションの信頼性を向上させ、セルラー接続でのデータ転送時間を最小限に抑える必要があります
どうすれば良いでしょうか?
- A.FTP サーバのGoogle Container Engine クラスタを1つ使用します。データを複数地域バケットに保存し、バケット内のデータを使用してETL プロセスの実行します。
- B. 異なる地域にあるFTP サーバを実行する複数のGoogle Container Engine クラスタを使用します。データを米国、EUおよびアジアの複数地域バケットに保存し、バケット内のデータを使用してETL プロセスを実行します。
- C. HTTP(S)上でGoogle API を使用して、米国、EU、アジア内のさまざまなGoogle Cloud Multi-Regional Storage バケット ロケーションにファイルを直接転送します。バケット内のデータを使用してETL プロセスを実行します。
- D. HTTP(S)上でGoogle API を使用して、米国、EU、アジア内の別のGoogle Cloud Regional Storage バケット ロケーションにファイルを直接転送します。ETL プロセスを実行して、各地域バケットからデータを取得します。
Correct Answer: D
QUESTION 27
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthの2,000万台の車は世界中に散らばっています。
車両の位置に基づいて、テレメトリデータはGoogle Cloud Storage(GCS)のリージョンバケット(米国、欧州、アジア)に保存されています。
CTOは、なぜ車が100キロ走行した後に故障しているのかを判断するために、生のテレメトリデータに関するレポートの作成を望んでいます。
このジョブをすべてのデータに対して実行します。
このジョブを実行するための最も費用対効果の高い方法はどれでしょうか?
- A. すべてのデータを1つのゾーンに移動し、Google Cloud Dataproc クラスタを起動してジョブを実行します。
- B. すべてのデータを1つのリージョンに移動してから、Google Cloud Dataproc クラスタを起動してジョブを実行します。
- C. 各地域でクラスタを起動して未処理データを前処理および圧縮し、データを複数地域のバケットに移動し、Google Cloud Dataproc クラスタを使用してジョブを終了します。
- D. 各リージョンでクラスタを起動して生データを前処理および圧縮し、データをリージョンバケットに移動し、Google Cloud Dataproc クラスタを使用してジョブを仕上げます。
Correct Answer: D
QUESTION 28
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthは、接続されているすべてのトラックにサーバとセンサーを搭載し、遠隔測定データを収集しています。
来年にこのデータを使用して機械学習モデルをトレーニングしたいと考えています。 またコストを削減しながら、このデータをパブリック クラウドに保存したいとも考えています。
何をすれば良いでしょうか?
- A. トラックのコンピューターに1時間ごとのスナップショットでデータを圧縮させ、Google Cloud Nearline Storage バケットに保存します。
- B. 遠隔測定データを、データを圧縮するストリーミングデータ フロージョブにリアルタイムでプッシュし、Google BigQuery に保存します。
- C. データを圧縮するストリーミングデータ フロージョブにリアルタイムで遠隔測定データをプッシュし、Google Cloud Bigtable に保存します。
- D. トラックのコンピューターに1時間ごとのスナップショットでデータを圧縮させ、Google Cloud Coldline Storage バケットに保存します。
Correct Answer: D
Explanation:
Coldline Storage は、年に 1 回程度しかアクセスしないデータに最適な選択肢です。可用性が若干低く、最小保存期間は 90 日です。データ アーカイブ、オンライン バックアップ、障害復旧のための非常に低コストで、耐久性に優れたストレージ サービスです。
<例>
・Google Cloud Coldline Storage:法律や規制上の理由で保存されたデータなど、アクセス頻度の低いデータは、Coldline Storage として低コストで保存でき、必要なときに利用できます。
・災害復旧:災害復旧が発生した場合は復旧時間が重要です。Google Cloud Storageは、Coldline Storageとして保存されたデータへの低レイテンシなアクセスを提供しています。
Reference:
–ストレージ クラス
QUESTION 29
この質問については、TerramEarth のケーススタディを参照してください。
農業部門は完全自動運転車の実験をしています。
車両の運用中に強力なセキュリティを強化するためのアーキテクチャが必要です。
どのアーキテクチャを検討する必要がありますか?(回答は2つ)
- A. 車両上のモジュール間のすべてのマイクロサービスコールを信頼できないものとして扱います。
- B. 安全なアドレス空間を確保するために、接続にIPv6 が必要です。
- C.トラステッドプラットフォームモジュール(TPM)を使用し、起動時にファームウェアとバイナリを確認します。
- D. 関数型プログラミング言語を使用して、コード実行サイクルを分離します。
- E. 冗長性のために複数の接続サブシステムを使用します。
- F. チップを分離するために、車両の駆動電子機器をファラデーケージに入れます。
Correct Answer: A、C
QUESTION 30
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthの各車両は、環境条件に応じて油圧などの運転パラメータを調整して効率を向上させることができます。
主な目標は、携帯電話と未接続の2,000万台すべての車両の現場での作業効率を向上させることです。
この目標を達成するには何をすれば良いでしょうか?
- A. データのパターンを検査し、動作調整を自動的に行うルールを使用してアルゴリズムを作成します。
- B. すべての動作データをキャプチャし、理想的な動作を特定する機械学習モデルをトレーニングし、ローカルで実行して自動的に動作調整を行います。
- C. スライディング ウィンドウでGoogle Cloud Dataflow ストリーミング ジョブを実装し、Google Cloud Messaging(GCM)を使用して運用上の調整を自動的に行います。
- D. すべての操作データをキャプチャし、理想的な操作を識別する機械学習モデルをトレーニングし、Google Cloud Machine Learning(ML)プラットフォームでホストして、操作を自動的に調整します。
Correct Answer: B
QUESTION 31
この質問については、TerramEarth のケーススタディを参照してください。
欧州連合の一般データ保護規則(GDPR)に準拠するために、TerramEarthは、個人データが含まれる36か月後にヨーロッパの顧客から生成されたデータを削除する必要があります。
新しいアーキテクチャでは、このデータはGoogle Cloud Storage とGoogle BigQuery の両方に保存されます。
何をするべきでしょうか?
- A. 欧州連合 データ用のGoogle BigQuery テーブルを作成し、テーブルの保存期間を36ヶ月に設定します。 Google Cloud Storageの場合、gsutil を使用して、36ヶ月のage 条件でDelete アクションを使用するライフサイクル管理を有効にします。
- B. 欧州連合 データ用のGoogle BigQuery テーブルを作成し、テーブルの保存期間を36ヶ月に設定します。Googel Cloud Storageの場合、36ヶ月のage 条件の場合、gsutil を使用してSetStorageClass to NONE アクションを作成します。
- C. 欧州連合 データ用のGoogle BigQuery タイムパーティション テーブルを作成し、パーティションの有効期限を36ヶ月に設定します。Google Cloud Storage の場合、gsutil を使用して、36ヶ月のage 条件でDelete アクションを使用するライフサイクル管理を有効にします。
- D. 欧州連合 データ用のGoogle BigQuery タイムパーティションテーブルを作成し、パーティション期間を36ヶ月に設定します。 Google Cloud Storageの場合、gsutilを使用して、36ヶ月のage 条件でSetStorageClass to NONE アクションを作成します。
Correct Answer: C
QUESTION 32
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthは、データファイルをGoogle Cloud Storage(GCS)に保存することを決定しました。
GCS のライフサイクル ルールを設定して、1年間のデータを保存しますが、ファイルス トレージのコストを最小限に抑える必要があります。
どうすればいいでしょうか?
- A.「 Age:30、Storage Class:Standard、アクション:Coldline に設定」でGCS のライフサイクル ルールを作成し、Age 条件で2つ目のGCS ライフサイクル ルールを作成します。
- Age:365、Storage Class:Coldline、アクション:Delete
- B. 「 Age:30、Storage Class:Cloudline、アクション:Nearline に設定」でGCS のライフサイクル ルールを作成し、Age 条件で2つ目のGCS ライフサイクル ルールを作成します。
- Age:91、Storage Class:Cloudline、アクション:Nearline に設定
- C. 「 Age:90、Storage Class:Standard、アクション:Nearline に設定」でGCS のライフサイクル ルールを作成し、Age 条件で2つ目のGCS ライフサイクル ルールを作成します。
- Age:91、Storage Class:Nearline、アクション:Coldline に設定
- D.「 Age:30、Storage Class:Standard、アクション:Coldline に設定」でGCS のライフサイクル ルールを作成し、Age 条件で2つ目のGCS ライフサイクル ルールを作成します。
- Age:365、Storage Class:Nearline、アクション:Delete
Correct Answer: A
QUESTION 33
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthのデータ ウェアハウスに、信頼性と拡張性に優れたGCP ソリューションを実装する必要があります。
TerramEarthのビジネス要件と技術的要件を考慮してください。
何をするべきでしょうか?
- A. 既存のデータ ウェアハウスをGoogle BigQueryに置き換え、パーティション分割テーブルを使用します。
- B. 既存のデータ ウェアハウスを96個のvCPUを持つGoogle Compute Engine インスタンスに置き換えます。
- C. 既存のデータ ウェアハウスをGoogle BigQuery に置き換え、外部データソース(フェデレーション データソース)を使用します。
- D. 既存のデータ ウェアハウスを96個のvCPUのGoogle Compute Engine インスタンスに置き換え、 32個のvCPUのGoogle Compute Engine プリエンプティブル インスタンスを追加します。
Correct Answer: A
QUESTION 34
この質問については、TerramEarth のケーススタディを参照してください。
すべての入力データをGoogle BigQuery に書き込む新しいアーキテクチャが導入されました。
データが汚れていることに気付き、コストを管理しながら、毎日自動化されたデータ品質を確保したいと考えています。
何をするべきでしょうか?
- A. Google Cloud Dataflow ストリーミング ジョブを設定し、取り込みプロセスでデータを受信します。 Google Cloud Dataflow パイプラインのデータをクリーンアップします。
- B. Google BigQuery からデータを読み取り、クリーンアップするGoogle Cloud Functions を作成します。Google Compute EngineインスタンスからGoogle Cloud Functions をトリガーします。
- C. Google BigQuery のデータにSQL文を作成し、ビューとして保存します。 ビューを毎日実行し、結果を新しいテーブルに保存します。
- D. Google Cloud Dataprep を使用して、Google BigQuery テーブルをソースとして構成します。 データを消去するために毎日のジョブをスケジュールします。
Correct Answer: D
QUESTION 35
この質問については、TerramEarth のケーススタディを参照してください。
TerramEarthの技術的要件を考慮した場合、Google Cloud Platform で予想外の車両のダウンタイムをどのように削減するべきですか?
- A. Google BigQuery をデータ ウェアハウスとして使用します。 すべての車両をネットワークに接続し、Google Cloud Pub/Sub とGoogle Cloud Dataflow を使用してデータをGoogle BigQuery にストリーミングします。分析とレポートにGoogle データポータル(データスタジオ) を使用します。
- B. Google BigQuery をデータ ウェアハウスとして使用します。すべての車両をネットワークに接続し、gcloud を使用してgzip ファイルをGoogle Cloud Multi-Regional Storage バケットにアップロードします。 分析とレポートにGoogle データポータルを使用します。
- C. Google Cloud Dataproc Hive をデータ ウェアハウスとして使用します。gzip ファイルをGoogle Cloud Multi-Regional Storage バケットにアップロードします。gcloud を使用して、このデータをGoogle BigQuery にアップロードします。分析とレポートにGoogle データポータルを使用します。
- D. Google Cloud Dataproc Hive をデータウェアハウスとして使用します。パーティション化されたHive テーブルにデータを直接ストリーミングします。Pig スクリプトを使用してデータを分析します。
Correct Answer: A
QUESTION 36
この質問については、TerramEarth のケーススタディを参照してください。
携帯電話ネットワークに接続されている20万台の車両のデータを取り込むための新しいアーキテクチャを設計するよう求められます。
Google のベストプラクティスに従ってください。
TerramEarthの技術的要件を考慮すると、データの取り込みにはどのコンポーネントを使用する必要がありますか。
- A. SSL Ingress を使用したGoogle Kubernetes Engine。
- B. 公開鍵 / 秘密鍵ペアを使用したGoogle Cloud IoT Core。
- C. プロジェクト全体のSSH 認証鍵を備えたGoogle Compute Engine。
- D. 特定のSSH 認証鍵を持つGoogle Compute Engine。
Correct Answer: B
QUESTION 37
この質問については、Dress4Win のケーススタディを参照してください。
Dress4Winのセキュリティチームは、Google Cloud Platform(GCP)上の運用仮想マシン(VM)への外部 SSH アクセスを無効しました。
運用チームはVMをリモートで管理し、Docker コンテナのビルドとプッシュし、Google Cloud Storage オブジェクトの管理を行う必要があります。
セキュリティチームは、運用チームに何をするべきでしょうか?
- A. 運用エンジニアにGoogle Cloud Shell へのアクセス権を付与します。
- B. GCP へのVPN 接続を構成し、GCP のVMへのSSH アクセスを許可します。
- C. 運用エンジニアがタスクを実行する必要がある場合に、GCP のVMへの一時的なSSH アクセスを許可する新しいアクセス要求プロセスを開発します。
- D. 開発チームにAPI サービスを構築して、運用チームが特定のリモート プロシージャ コール(RPC)を実行してタスクを実行できるようにします。
Correct Answer: A
QUESTION 38
この質問については、Dress4Win のケーススタディを参照してください。Dress4Winでは、運用エンジニアが、データベースのバックアップ ファイルのコピーをリモートでアーカイブするための低コストのソリューションを作成しようとしています。
データベース ファイルは、現在のデータセンターに格納されている圧縮 tar ファイルです。
何をするべきでしょうか?
- A. gsutil を使用してcron スクリプトを作成し、ファイルをColdline Storage バケットにコピーします。
- B. gsutil を使用してcron スクリプトを作成し、ファイルをRegional Storage バケットにコピーします。
- C. Google Cloud Storage Transfer Service ジョブを作成して、ファイルをColdline Storage バケットにコピーします。
- D. Google Cloud Storage Transfer Service ジョブを作成して、ファイルをRegional Storage バケットにコピーします。
Correct Answer: A
Explanation:
gsutil とGoogle Cloud Storage Transfer Serviceのどちらを使用するかを決定する際は、次のルールに従ってください。
- オンプレミスのロケーションからデータを転送する場合は、gsutil を使用します。
- 別のクラウド ストレージ プロバイダからデータを転送する場合は、Google Cloud Storage Transfer Service を使用します。
- それ以外の場合は、具体的な状況を勘案して両方のツールを評価してください。
このガイダンスをベースとして使用します。転送シナリオの詳細は、適切なツールを判断するときにも役立ちます。
Rerence:
– Storage Transfer Service の概要
QUESTION 39
この質問については、Dress4Win のケーススタディを参照してください。Dress4Winは、アプリケーション サーバで使用するマシンタイプの導入を検討しています。
何をするべきでしょうか?
- A. オンプレミスの物理ハードウェア コアとRAMをパブリック クラウド内の最も近いマシンタイプにマッピングします。
- B. Dress4Winには、CPUに対するRAMの比率が最も高いマシンタイプにアプリケーション サーバを導入することをお勧めします。
- C. Dress4Winには、最小のインスタンスを使用して本番環境に導入し、時間をかけて監視し、目的のパフォーマンスに達するまでマシンタイプをスケールアップすることをお勧めします。
- D. アプリケーション サーバの仮想マシンに関連付けられた仮想コアとRAMの数を特定し、パブリック クラウド内のカスタム マシンタイプに合わせてパフォーマンスを監視し、目的のパフォーマンスに達するまでマシンタイプをスケールアップします。
Correct Answer: C
QUESTION 40
この質問については、Dress4Win のケーススタディを参照してください。
Dress4Winのパブリック クラウドへの移行計画の一環として、トラフィック負荷の急増に対処できるようにロギングとモニタリングの管理システムをセットアップしたいと考えています。
Dress4Winが希望する保証項目:
- インフラストラクチャは、1日の使用量の増減を処理するためにスケールアップおよびスケールダウンが必要になったときの通知。
- アプリケーションがエラー報告したときの管理者に自動通知。
- 集約されたログをフィルタリングして、多くのホストでアプリケーションの一部をデバッグ。
Google StackDriver のどの機能を使うべきか?
- A. Logging、Alerts、Insights、Debug。
- B. Monitoring, Trace, Debug, Logging。
- C. Monitoring, Logging, Alerts, Error Reporting。
- D. Monitoring, Logging, Debug, Error Report。
Correct Answer: D
QUESTION 41
この質問については、Dress4Win のケーススタディを参照してください。
Dress4Winは、一部のアプリケーションをそのまま迅速に正常にデプロイすることにより、パブリック クラウドへのアプリケーションのデプロイに精通したいと考えています。
何を行えばよいでしょうか?
- A. パブリック クラウドへの最初の移行として、外部に依存する自己完結型アプリケーションを特定します。
- B. 内部的に依存しているエンタープライズアプリケーションを特定し、パブリック クラウドへの最初の移行します。
- C. 社内データベースをパブリック クラウドに移行し、オンプレミス アプリケーションへのリクエストを継続的に処理します。
- D. メッセージ キュー サーバをパブリック クラウドに移動し、オンプレミス アプリケーションへのリクエストの処理を続行します。
Correct Answer: C
QUESTION 42
この質問については、Dress4Win のケーススタディを参照してください。
Dress4Winは、オンプレミスのMySQL 環境をパブリック クラウドに移行する方法についてアドバイスを求めています。
移行中の自社運用ソリューションへのダウンタイムとパフォーマンスの影響を最小限に抑えたいと考えています。
何をすれば良いでしょうか?
- A. オンプレミス MySQL マスターサーバのダンプ(dump)ファイルを作成し、シャットダウンしてパブリック クラウド環境にアップロードし、新しいMySQL クラスタにロードします。
- B. パブリック クラウド環境でMySQL レプリカサーバ/スレーブを設定し、カットオーバまでオンプレミスのMySQL マスターサーバから非同期レプリケーション用に構成します。
- C. パブリック クラウドに新しいMySQL クラスタを作成し、オンプレミスとパブリック クラウドの両方のMySQL マスターへの書き込みを開始するようにアプリケーションを構成し、カットオーバー時に元のクラスタを破棄します。
- D. MySQL レプリカサーバのダンプ ファイルをパブリック クラウド環境に作成してGoogle Cloud Datastore にロードし、カットオーバ時にGoogle Cloud Datastore に対して読み取り/書き込みを行うようにアプリケーションを構成します。
Correct Answer: B
QUESTION 43
この質問については、Dress4Win のケーススタディを参照してください。
Dress4Winは、従来のサービスのいくつかについて、Google Stackdriver で新しい稼働時間チェックを設定しました。
Stackdriver ダッシュボードは、サービスが正常であると報告していません。
何をするべきでしょうか?
- A. すべての従来のWebサーバにStackdriver エージェントをインストールします。
- B. Google Cloud Platform Console で、アップタイムサーバのIP アドレスのリストをダウンロードし、インバウンド ファイアウォール ルールを作成します。
- C. 値がGoogleStackdriverMonitoring-UptimeChecks と一致したときにUser-Agent HTTP ヘッダーを通過するようにロードバランサーを構成します。(https://cloud.google.com/monitoring)
- D. 値がGoogleStackdriverMonitoringUptimeChecks と一致する場合、user-Agent HTTPヘッダーを含むリクエストを許可するように従来のWebサーバーを設定します。(https://cloud.google.com/monitoring)
Correct Answer: B
QUESTION 44
この質問については、Dress4Win のケーススタディを参照してください。
新しいアプリケーション体験の一環として、Dress4Wmでは顧客が自分の画像をアップロードできます。
顧客は、これらのイメージを表示できるユーザーを独占的に管理できます。
顧客は、最小限の待ち時間で画像をアップロードでき、ログイン時にメイン アプリケーション ページに画像をすばやく表示できる必要があります。
どの構成を使用するべきでしょうか?
- A. Google Cloud Storage バケットに画像ファイルを保存します。Google Cloud Datastore を使用して、各顧客のIDとその画像ファイルをマッピングするメタデータを維持します。
- B. Google Cloud Storage バケットに画像ファイルを保存します。顧客の一意のIDを含むGoogle Cloud Storageのアップロードされた画像にカスタムメタデータを追加します。
- C. 分散ファイルシステムを使用して、顧客の画像を保存します。ストレージのニーズが増えたときには、永続ディスクやノードを追加します。各ファイルの所有者属性を設定する一意のIDを各顧客に割り当て、画像のプライバシーを確保します。
- D. 分散ファイルシステムを使用して、顧客の画像を保存します。ストレージのニーズが増えたときには、永続ディスクやノードを追加します。Google Cloud SQL データベースを使用して、各顧客のIDを画像ファイルにマッピングするメタデータを維持します。
Correct Answer: A
QUESTION 45
この質問については、Dress4Win のケーススタディを参照してください。
Dress4Winには、エンドポイントの100%をカバーするエンドツーエンドのテストがあります。
パブリック クラウドへの移行によって新しいバグが発生しないようにしたいと考えています。
停止を防ぐために開発者はどのような追加のテスト方法を採用するべきですか?
- A. アプリケーション コードでGoogle Stackdriver Debugger を有効にして、コード内のエラーを表示する必要があります。
- B. パブリック クラウドのステージング環境にユニット(単体)テストと実稼働規模の負荷テストを追加する必要があります。
- C. パブリック クラウドのステージング環境でエンドツーエンドのテストを実行して、コードが意図したとおりに機能しているかどうかを判断する必要があります。
- D. カナリアテストを追加して、開発者が新しいリリースが遅延に与える影響を測定できるようにします。
Correct Answer: B
QUESTION 46
この質問については、Dress4Win のケーススタディを参照してください。
Dress4Winの販売記録と税記録は、監査人が少なくとも10年間は見ることはありません。
最優先事項は、コストの最適化です。
どのGoogle プロダクトを選択するべきでしょうか?
- A. データはGoogle Cloud Coldline Storage に保存し、gsutil でデータにアクセスします。
- B. データはGoogle Cloud Nearline Storage に保存し、gsutil でデータにアクセスします。
- C. データはアメリカまたはヨーロッパ リージョンを指定し、Google Bigtabte に保存し、gcloud でデータにアクセスします。
- D.データはGoogle BigQuery に保存し、マネージド インスタンス グループ(MIG)内のWebサーバ クラスタでデータにアクセスします。Google Cloud SQL に、データを格納するために2つの異なるリージョンにミラーリングを行い、マネージド インスタンス グループ(MIG)内のRedis クラスタにミラーリングされたデータにアクセスします。
Correct Answer: A
Reference:
– ストレージ クラス
QUESTION 47
この質問については、Dress4Win のケーススタディを参照してください。
現在のDress4winのシステム アーキテクチャは、1つのデータセンターに配置されているため、一部のお客様によってはレーテンシーが高くなることがあります。
パブリック クラウドでのパフォーマンスの将来の評価と最適化の時点で、Dresses4winは、Google Cloud Platform のシステムアーキテクチャを複数の場所に配布したいと考えています。
どのアプローチを採用するべきですか?
- A. リージョン マネージド インスタンス グループとグローバル負荷分散を使用してパフォーマンスを向上させます。リージョン マネージド インスタンス グループは、トラフィックに基づいて各地域のインスタンスを個別に拡大できるためです。
- B. 運用チームが管理する仮想マシンのより近いグループにリクエストを転送する仮想マシンのセットでグローバル負荷分散を使用します。
- C.リージョン マネージド インスタンス グループとグローバル負荷分散を使用して、異なるリージョンのゾーン間で自動フェールオーバーを提供することにより、信頼性を向上させます。
- D. 個別のマネージド インスタンス グループの一部として、リクエストをより近い仮想マシンのグループに転送する一連の仮想マシンでグローバル負荷分散を使用します。
Correct Answer: A
Rerence:
– グローバル負荷分散によるアプリケーションの処理能力の改善
– リージョン マネージド インスタンス グループを使用したインスタンスの分散
QUESTION 48
この質問については、Dress4Win のケーススタディを参照してください。
Dress4Winは、既存の使用パターンを反映したデータとトラフィックの対応する成長とともに、1年でそのサイズの10倍に成長すると予想されます。
CIOは、今後6ヵ月以内に運用しているインフラストラクチャをパブリック クラウドに移行するという目標を設定しました。
アプリケーションに大きな変更することなく、この成長に合わせて拡張し、ROI を最大化するようにソリューションをどのように構成すれば良いでしょうか?
- A. Web アプリケーション レイヤーをGoogle App Engine に、MySQL をGoogle Cloud Datastore に、NASをGoogle Cloud Storage に移行します。RabbitMQ をデプロイし、Google Cloud Deployment Manager を使ってHadoop サーバをデプロイします。
- B. RabbitMQ をGoogle Cloud Pub/Subに、Hadoop をGoogle BigQueryに、NASをGoogle Compute Engine とPersistent Disk ストレージに移行します。Tomcat をデプロイして、Google Cloud Deployment Manager を使ってNginx をデプロイします。
- C. Tomcat およびNginx 用のマネージド インスタンス グループを実装します。MySQL をGoogle Cloud SQL に、RabbitMQ をGoogle Cloud Pub/Sub に、Hadoop をGoogle Cloud Dataproc に、NAS をGoogle Compute Engine とPersistent Disk ストレージに移行します。
- D. Tomcat およびNginx 用のマネージド インスタンス グループを実装します。MySQL をGoogle Cloud SQL に、RabbitMQ をGoogle Cloud Pub/Sub に、Hadoop をGoogle Cloud Dataproc に、NASをGoogle Cloud Storage に移行します。
Correct Answer: D
QUESTION 49
この質問については、Dress4Win のケーススタディを参照してください。
特定のビジネス要件を考慮して、Webおよびトランザクション データレイヤーの導入をどのように自動化すれば良いでしょうか?
- A. Google Cloud Deployment Manager を使用して、Nginx とTomcat をGoogle Compute Engine にデプロイします。 MySQL を置き換えるCloud SQL サーバをデプロイします。Google Cloud Deployment Manager を使用してJenkins を展開します。
- B. Google Cloud Platform(GCP)Marketplace を使用してNginx とTomcat を展開します。GCP Marketplace を使用してMySQL サーバを展開します。Google Cloud Deployment Manager スクリプトを使用して、Jenkins をGoogle Compute Engine にデプロイします。
- C. Nginx とTomcat をGoogle App Engine に移行します。Google Cloud Datastore サーバをデプロイして、高可用性構成のMySQL サーバを置き換えます。GCP Marketplace を使用してJenkins をGoogle Compute Engine にデプロイします。
- D. Nginx とTomcat をGoogle App Engine に移行します。GCP Marketplace を使用してMySQL サーバを展開します。GCP Marketplace を使用してJenkins をGoogle Compute Engine にデプロイします。
Correct Answer: A
QUESTION 50
この質問については、Dress4Win のケーススタディを参照してください。
どのコンピューティングサービスをそのまま移行を行うと、パブリック クラウドでのパフォーマンスのために最適化されたアーキテクチャになりますか?
- A. Google App Engine スタンダード環境を使用して展開されたWebアプリケーション。
- B.管理されていないインスタンス グループを使用して展開されたRabbitMQ。
- C.高可用性モードでGoogle Cloud Dataproc Regional を使用して展開されたHadoop/Spark。
- D.ジェンキンス、監視、要塞ホスト、カスタムマシンタイプに展開されたセキュリティスキャナーサービス。
Correct Answer: A
QUESTION 51
この質問については、Dress4Win のケーススタディを参照してください。
監査中に法令に準拠するためには、Dress4WinはGoogle Cloud 上のリソース構成やメタデータを変更するすべての管理アクションを洞察できなければなりません。
何をするべきでしょうか?
- A. Stackdriver Trace を使用して、トレースリスト分析を作成します。
- B. Stackdriver Monitoring を使用して、プロジェクトのアクティビティに関するダッシュボードを作成します。
- C. すべてのプロジェクトでCloud Identity-Aware Proxy を有効にし、管理者(Administrators)グループをメンバーとして追加します。
- D. Google Cloud Platform Console のアクティビティページとStackdriver Logging を使用して、必要な洞察を提供します。
Correct Answer: D
QUESTION 52
この質問については、Dress4Win のケーススタディを参照してください。Dress4WinのGoogle Cloud Storage に保存されたデータのセキュリティに責任があります。
既にGoogle グループのセットを作成し、適切なユーザーをそれらのグループに割り当てています。
Google ベストプラクティスに従って、ビジネス要件と技術的要件を満たすために最も単純な設計を実装する必要があります。
何をするべきでしょうか?
- A. セキュリティ要件を実施するために、作成したGoogl eグループにIAMのカスタムの役割を割り当てます。Google Cloud Storage にファイルを保存するときに、顧客が用意した暗号鍵でデータを暗号化します。
- B. セキュリティ要件を実施するために、作成したGoogle グループにIAMのカスタムの役割を割り当てます。Google Cloud Storage にファイルを保存する前に、デフォルトのストレージ暗号化を有効します。
- C. セキュリティ要件を実施するために、作成したGoogle グループに定義済みのIAMの役割を割り当てます。Google Cloud Storage にファイルを保存するときに、Google のデフォルトの暗号化を保存時に使用します。
- D. セキュリティ要件を実施するために、作成したGoogle グループに定義済みのIAM の役割を割り当てます。Google Cloud Storage にファイルを保存する前に、デフォルトのGoogle Cloud KMS の暗号鍵が設定されていることを確認します。
Correct Answer: C
QUESTION 53
この質問については、Dress4Win のケーススタディを参照してください。
ソリューションを移行する前に、オンプレミス アーキテクチャがビジネス要件を満たしていることを確認する必要があります。
オンプレミスのアーキテクチャをどのように変更する必要がありますか?
- A. RabbitMQ をGoogle Cloud Pub / Subに置き換えます。
- B. MySQL をGoogle Cloud SQL for MySQL でサポートされているv5.7にダウングレードします。
- C. 事前定義されたGoogle Compute Engine マシンタイプに一致するようにコンピューティング リソースのサイズを変更します。
- D. マイクロサービスをコンテナ化し、Google Kubernetes Engine でホストします。
Correct Answer: C
QUESTION 54
会社のテストスイートは、Linux 仮想マシンで毎日テストを実行するカスタム C ++ アプリケーションです。
完全なテストスイートの完了には数時間かかり、テスト用に予約された限られた数のオンプレミスサーバーで実行されます。
会社は、テスト インフラストラクチャをパブリッククラウドに移行し、システムへの変更を完全にテストするのにかかる時間を削減し、テストの変更をできる限り少なくしたいと考えています。
どのクラウドインフラストラクチャになりますか?
- A. Google Compute Engine の非マネージ ドインスタンス グループとネットワーク負荷分散。
- B. 自動スケーリングを使用したGoogle Compute Engine マネージド インスタンス グループ。
- C. Apache Cloud Hadoop ジョブを実行して各テストを処理するGoogle Cloud Dataproc。
- D. ロギング用のGoogle StackDriver を備えたGoogle App Engine。
Correct Answer: B
Explanation:
Google Compute Engine を使用すると、ユーザーはオンデマンドで仮想マシン(VM)を起動できます。 VMは、ユーザーが作成した標準イメージまたはカスタムイメージから起動できます。
マネージド インスタンス グループは、負荷の増減に基づいてマネージ ドインスタンス グループにインスタンスを自動的に追加または削除できる自動スケーリング機能を提供します。自動スケーリングは、アプリケーションがトラフィックの増加を適切に処理し、リソースの必要性が低い場合にコストを削減するのに役立ちます。
Incorrect Answers:
B:カスタムC ++ アプリケーションの着信 IP データ トラフィックに関する言及はありません。
C:Apache Hadoop は、C ++ アプリケーションのテストには適していません。 Apache Hadoop は、MapReduce プログラミングモデルを使用したビッグデータのデータセットの分散ストレージおよび処理に使用されるオープンソースのソフトウェア フレームワークです。
D:Google App Engine は、Webアプリケーションで使用することを目的としています。
Google App Engine は、Google が管理するデータセンターでWebアプリケーションを開発およびホストするためのWebフレームワークおよびクラウド コンピューティング プラットフォームです。
Reference:
– 基礎知識 (opens in a new tab)”>インスタンスのグループの自動スケーリング>基礎知識
QUESTION 55
最近の監査で、Google Cloud Platform のプロジェクトで新しいネットワークが作成されたことが明らかになりました。
このネットワークでは、Google Compute Engine(GCE)インスタンスのSSHポートが公開されており、ネットワークの発信元を検出する必要があります。
何をするべきでしょうか?
- A. Stackdriver Alerting Console でCreate VM エントリを検索します
- B. [ホーム] セクションの[アクティビティ] ページに移動します。カテゴリをデータアクセスに設定し、VM エントリの作成を検索します
- C. コンソールのログセクションで、ログセクションとしてGCE ネットワークを指定します。挿入の作成エントリを検索します。
- D. プロジェクト SSH キーを使用してGCE インスタンスに接続します。システムログで以前のログインを特定し、プロジェクト 所有者リストと一致させます。
Correct Answer: C
Incorrect Answers:
A:Stackdriver Alerting Console を使用するには、最初にアラートポリシーを設定する必要があります。
B:データアクセスログには読み取り専用操作のみが含まれます。
監査ログは、誰が何を、どこで、いつ行ったかを判断するのに役立ちます。
Google Cloud Audit Logging は、2種類のログを返します。
管理アクティビティログ、データアクセスログ:読み取り専用操作を実行する操作のログエントリが含まれます。get、list、aggregated listメソッドなどのデータは変更されません。
QUESTION 56
会社は、単一のMySQLインスタンスで複数のデータベースを実行しています。
定期的に特定のデータベースのバックアップを取る必要があります。
バックアップ アクティビティはできるだけ早く完了する必要があり、ディスクのパフォーマンスに影響しないようにします。
ストレージをどのように構成する必要がありますか?
- A. gcloudツールを使用して永続的なディスクスナップショットを使用して定期的なバックアップを取るようにcronジョブを構成します。
- B. バックアップ場所としてローカル SSD ボリュームをマウントします。 バックアップが完了したら、gsutil を使用してバックアップをGoogle Cloud Storage に移動します。
- C. gcsfise を使用して、Google Cloud Storage バケットをインスタンスに直接ボリュームとしてマウントし、mysqldump を使用してマウントされた場所にバックアップを書き込みます。
- D. 追加の永続ディスクボリュームをRAID 10 アレイの各仮想マシン(VM)インスタンスにマウントし、LVM を使用してスナップショットを作成し、Google Cloud Storage に送信します。
Correct Answer: B
QUESTION 57
実行中のGoogle Kubernetes Engine クラスタを有効にして、アプリケーションの需要に応じてスケーリングできるようにします。
あなたは何をするべきか?
- A.次のコマンドを使用して、Kubernetes Engine クラスタにノードを追加します。
- gcloud container clusters resize
- CLUSTER_Name – -size 10
- B. 次のコマンドを使用して、クラスタ内のインスタンスにタグを追加します。
- gcloud compute instances add-tags
- INSTANCE – -tags enableautoscaling max-nodes-10
- C. 次のコマンドを使用して、既存のGoogle Kubernetes Engine クラスタを更新します。
- gcloud alpha container clusters
- update mycluster – -enableautoscaling – -min-nodes=1 – -max-nodes=10
- D. 次のコマンドを使用して、新しいGoogle Kubernetes Engine クラスタを作成します。
- gcloud alpha container clusters
- create mycluster – -enableautoscaling – -min-nodes=1 – -max-nodes=10
- and redeploy your application
Correct Answer: C
QUESTION 58
運用マネージャーは、J2EE アプリケーションをパブリック クラウドに移行する際に考慮する必要がある推奨プラクティスのリストを尋ねます。
どの3つのプラクティスをお勧めしますか?(回答は3つ)
- A.アプリケーションコードを移植して、Google App Engine で実行します。
- B. Google Cloud Dataflow をアプリケーションに統合して、リアルタイムのメトリックをキャプチャします。
- C. Stackdriver Debugger などの監視ツールを使用してアプリケーションを計測します。
- D.自動化フレームワークを選択して、クラウド インフラストラクチャを確実にプロビジョニングします。
- E.ステージング環境で自動テストを使用して継続的統合ツールを展開します。
- F. MySQL からGoogle Cloud Datastore やGoogle Cloud Bigtable などの管理されたNoSQL データベースに移行します。
Correct Answer: A, D, E
References:
– Java アプリをデプロイする
– 入門: Cloud SQL
QUESTION 59
会社は、スケジュールされた会議用に予約された会議室に誰かがいるかどうかを追跡したいと考えています。
3大陸の5つのオフィスに1,000の会議室があり、各部屋に状態を毎秒報告するモーションセンサーが設置されています。
モーションセンサーからのデータには、センサーIDといくつかの異なる個別の情報項目のみが含まれます。
アナリストは、アカウント所有者とオフィスの場所に関する情報とともに、このデータを使用します。
どのデータベースタイプを使用するべきでしょうか?
- A. Flat file
- B. NoSQL
- C. Relational
- D. Blobstore
Correct Answer: B
Explanation:
リレーショナル データベースは、現代のアプリケーションが直面する規模と俊敏性の課題に対処するように設計されておらず、今日利用可能なコモディティストレージと処理能力を活用するように構築されていません。
NoSQLは以下に適しています:
開発者は、構造化データ、半構造化データ、非構造化データ、多態性データなど、急速に変化する大量の新しいデータ型を作成するアプリケーションを使用しています。
Incorrect Answers:
D: Blobstore API を使用すると、アプリケーションは、データストア サービスのオブジェクトに許可されているサイズよりもはるかに大きい、ブロブと呼ばれるデータ オブジェクトを提供できます。
Blobstoreは、動画ファイルや画像ファイルなどの大きなファイルを処理する場合や、ユーザーが大きなデータファイルをアップロードできるようにする場合に便利です。
Reference:
– NoSQL Databases Explained
QUESTION 60
顧客は、最近更新したGoogle App Engine アプリケーションが一部のユーザーでの読み込みに約30秒かかっているという報告を受けています。
この動作は、更新前には報告されていませんでした。
どうすればいいでしょうか?
- A. ISPと協力して問題を診断します。
- B. 問題を診断するためにネットワークキャプチャとフローデータを要求するサポートチケットを開き、アプリケーションをロールバックします。
- C. 最初に以前の既知の正常なリリースにロールバックし、次にStackdriver Trace とStackdriver Logging を使用して、開発/テスト/ステージング環境で問題を診断します。
- D. 既知の正常なリリースにロールバックし、アクセスが少ない時間にリリースを再度プッシュして調査し、Stackdriver Trace とStackdriver Logging を使用して問題を診断します。
Correct Answer: C
Explanation:
Stackdriver Logging を使用することで、Google Cloud Platform およびAmazon Web Services(AWS)からのログデータとイベントを保存、検索、分析、監視、およびアラートできます。また、API を使用すると、任意のソースからカスタムログデータを取り込むことができます。Stackdriver Logging は、大規模に実行され、数千のVMからアプリケーションおよびシステムログデータを取り込むことができる完全に管理されたサービスです。さらにすべてのログデータをリアルタイムで分析できます。
Reference:
– Stackdriver Logging
QUESTION 61
Google Compute Engine の本番環境のデータベース仮想マシンには、データファイル用のext4 フォーマットの永続ディスクがあります。
データベースのストレージ容量が不足しています。
ダウンタイムを最小限に抑え、問題を解決するにはどうすれば良いでしょうか?
- A. Google Cloud Platform(GCP) Console で、永続ディスクのサイズを増やし、Linux でresize2fs コマンドを使用します。
- B. 仮想マシンをシャットダウンし、GCP Console を使用して永続ディスクサイズを増やしてから、仮想マシンを再起動します。
- C. GCP Consoleで、永続ディスクのサイズを増やし、Linux のfdisk コマンドで新しいスペースが使用できる状態になっていることを確認します。
- D. GCP Consoleで、仮想マシンに接続された新しい永続ディスクを作成し、フォーマットしてマウントし、データベースサービスを構成して、ファイルを新しいディスクに移動します。
- E. GCP Consoleで、永続ディスクのスナップショットを作成し、スナップショットを新しい大きなディスクに復元し、古いディスクをアンマウントし、新しいディスクをマウントして、データベースサービスを再起動します。
Correct Answer: A
Explanation:
Linux インスタンスでは、インスタンスに接続し、パーティションとファイルシステムのサイズを手動で変更して、追加した追加のディスクスペースを使用します。追加したスペースを使用するには、ディスクまたはパーティション上のファイルシステムを拡張します。 ディスクのパーティションを拡大した場合、パーティションを指定します。 ディスクにパーティションテーブルがない場合は、ディスク IDのみを指定します。
sudo resize2fs /dev/[DISK_ID][PARTITION_NUMBER]
[DISK_ID]はデバイス名、[PARTITION_NUMBER]はファイルシステムのサイズを変更するデバイスのパーティション番号です。
Reference:
– ゾーン永続ディスクの追加またはサイズ変更
QUESTION 62
会社では、ローカルデータセンターで実行されるApache Spark およびHadoop ジョブの数とサイズが急激に増加すると予測しています。
パブリック クラウドを利用して、最小限の運用作業とコード変更でこの今後の需要を拡大できるようにします。
どのGoogle Cloud Platafromプロダクトを使用するべきでしょうか?
- A. Google Cloud Dataflow
- B. Google Cloud Dataproc
- C. Google Compute Engine
- D. Google Kubernetes Engine
Correct Answer: B
Explanation:
Google Cloud Dataproc は、Google Cloud Platform 上でApache Spark およびApache Hadoop エコシステムを実行でき、高速で使いやすく、低コストで完全に管理されたサービスです。Google Cloud Dataproc は大規模または小規模のクラスターを迅速にプロビジョニングし、多くの一般的なジョブタイプをサポートし、Google Cloud Storage やStackdriver Logging などの他のGoogle Cloud Platform サービスと統合されているため、TCOの削減に役立ちます。
Reference:
– Cloud Dataproc FAQ
QUESTION 63
正確なリアルタイムの天気図作成アプリケーションのパフォーマンスを最適化する必要があります。
データは5万個のセンサーから発信され、タイムスタンプとセンサーの読み取り値の形式で毎秒10回の読み取り値が送信されます。
どのGoogle Cloud Platform プロダクトにデータを保存するべきでしょうか?
- A. Google BigQuery
- B. Google Cloud SQL
- C. Google Cloud Bigtable
- D. Google Cloud Storage
Correct Answer: C
Explanation:
Google Cloud Bigtable は、リアルタイム アクセスと分析ワークロードの両方に適した、スケーラブルで完全に管理されたNoSQL ワイドカラム データベース サービスです。
Good for:
低レイテンシの読み取り/書き込みアクセス
高スループット解析
ネイティブの時系列サポート
Common workloads:
IoT、ファイナンス、アドテック
モニタリング
Monitoring
地理空間データセット
グラフ
Reference:
– クラウド ストレージ プロダクト
QUESTION 64
マイクロサービス ベースのアプリケーションに対する少数のAPI リクエスト数が少ないと、非常に時間がかかります。
API への各リクエストは多くのサービスを通過できることがわかっています。どのサービスが最も時間がかかるかを望んでいます。
何をするべきでしょうか?
- A. 要求をより速く失敗できるように、アプリケーションにタイムアウトを設定します。
- B. 各リクエストのカスタムメトリックスをStackdriver Monitoring に送信します。
- C. Stackdriver Monitoring を使用して、API レイテンシーが高いときに表示される洞察を探します。
- D. Stackdriver Trace を使用してアプリケーションをインスツルメントし、各マイクロサービスでリクエストのレイテンシーを分解します。
Correct Answer: D
Reference:
– トレースの検索 (opens in a new tab)”>クイックスタート>トレースの検索
QUESTION 65
監査人は12か月ごとにチームを訪問し、過去12か月のすべてのGoogle Cloud IDおよびアクセス管理(Google Cloud IAM)ポリシーの変更を確認するよう求められています。
分析と監査プロセスを合理化と迅速化する必要があります。
何をするべきでしょうか?
- A.カスタム Google Stackdriver アラートを作成し、監査員に送信します。
- B. Google BigQuery へのログのエクスポートを有効にし、ACLとビューを使用して監査人と共有するデータの範囲を限定します。
- C.Google Cloud Functions を使用してログエントリをGoogle Cloud SQL に転送し、ACLとビューを使用して監査人のビューを制限します。
- D. Google Cloud Storage(GCS)ログのエクスポートを有効にして、ログをGCS バケットに監査し、バケットへのアクセスを委任します。
Correct Answer: D
QUESTION 66
リードエンジニアが、従来のデータセンターに仮想マシンを展開するカスタムツールを作成しました。
カスタムツールを新しいクラウド環境に移行したいと考え、Google Cloud Deployment Manager の採用を検討しています。。
GoogleCloud Deployment Manager に移行するビジネスリスクは何でしょうか?(回答は2つ)
- A. Google Cloud Deployment Manager はPython を使用します。
- B. Google Cloud Deployment Manager API は将来廃止される可能性があります。
- C. Google Cloud Deployment Manager は会社のエンジニアには馴染みがありません。
- D. Google Cloud Deployment Manager を実行するには、Google API サービス アカウントが必要です。
- E. Google Cloud Deployment Manager を使用して、クラウドリソースを完全に削除できます。
- F. Google Cloud Deployment Manager は、Google Cloud リソースの自動化のみをサポートしています。
Correct Answer: B、F
QUESTION 67
組織には、Google Cloud Platform(GCP) の同じネットワークに展開された3層のWebアプリケーションがあります。
各層(Web、API、データベース)は、他の層とは独立してスケーリングします。ネットワーク トラフィックは、Webを介してAPI 層に流れ、次にデータベース層に流れます。Webとデータベース層の間をトラフィックが流れてはなりません。
どのようなネットワーク構成にする必要がありますか?
- A. 各層を異なるサブネットワークに追加します。
- B. 個々のVMにソフトウェアベースのファイアウォールをセットアップします。
- C. タグを各層に追加し、ルートを設定して、目的のトラフィック フローを許可します。
- D. 各層にタグを追加し、ファイアウォール ルールを設定して、目的のトラフィックフローを許可します。
Correct Answer: D
Explanation:
GCP は、ルールとタグを通じてファイアウォールルールを実施します。 GCP ルールとタグは一度定義すれば、すべての地域で使用できます。
Reference:
– OpenStack ユーザーのための Google Cloud Platform
– Building three-tier architectures with security groups
QUESTION 68
開発チームは、Google Compute Engine(GCE)仮想マシン(VM)のバッチサーバーに新しいLinux カーネルモジュールをインストールして、夜間のバッチプロセスを高速化しました。
インストールの2日後、バッチサーバーの50%が夜間のバッチ実行に失敗しました。
開発チームに渡すための失敗に関する詳細を収集する必要があります。
どのアクションを実行するべきでしょうか?(回答は3つ)
- A. Stackdriver Logging を使用して、モジュールログエントリを検索します。
- B. API またはGoogle Cloud Platform(GCP)Console を使用して、GCE のデバッグ アクティビティログを読み取ります。
- C. gcloud またはGCP Console を使用してシリアルコンソールに接続し、ログを確認します。
- D. アクティビティログで、障害が発生したサーバのライブ マイグレーション イベントが発生したかどうかを特定します。
- E. Google Stackdriver のタイムラインを障害時間に合わせて調整し、バッチサーバ メトリックを観察します。
- F. デバッグ VMをイメージにエクスポートし、カーネルログ メッセージがネイティブ画面に表示されるローカルサーバでイメージを実行します。
Correct Answer: A、C、E
QUESTION 69
会社は、低リスクでパブリック クラウドを試してみたいと思っています。
約100 TBのログデータをパブリック クラウドにアーカイブし、そこで利用可能な分析機能をテストすると同時に、そのデータを長期の災害復旧バックアップとして保持したいと考えています。
どの手段を選択するべきでしょうか?(回答は2つ)
- A.ログをGoogle BigQuery にロードします。
- B.ログをGoogle Cloud SQL にロードします。
- C.ログをGoogle Stackdriver にインポートします。
- D.ログをGoogle Cloud Bigtable にインポートします。
- E.ログファイルをGoogle Cloud Storage にアップロードします。
Correct Answer: A、E
QUESTION 70
カスタム Java アプリケーションをGoogle App Engine にデプロイします。
デプロイに失敗し、次のスタックトレースが表示されます。
何をするべきでしょうか?
java.lang.SecurityException: SHA1 diest digest error for com/Altostart/CloakeServlet.class
at com.google.appengine.runtime.Request.prosess-d36f818a24b8cf1d (Request.java)
at sun.security.util.ManifestEntryVerifier.verify (ManifestEntryVerifier.java:210)
at.java.util.har.JarVerifier.prosessEntry (JarVerifier.java:218)
at java.util.jar.JarVerifier.update (JarVerifier.java:205)
at java.util.jar.JarVerifiersVerifierStream.read (JarVerifier.java:428)
at sun.misc.Resource.getBytes (Resource.java:124)
at java.net.URL.ClassLoader.defineClass (URCClassLoader.java:273)
at sun.reflect.GenerateMethodAccessor5.invoke (Unknown Source)
at sun.reflect.DelegatingMethodAccessorImp1.invoke (DelegatingMethodAccessorImp1.java:43)
at java.lang.reflect.Method.invoke (Method.java:616)
at java.lang.ClassLoader.loadClass (ClassLoader.java:266)- A. 不足しているJAR ファイルをアップロードし、アプリケーションを再デプロイします。
- B. すべてのJARファイルにデジタル署名し、アプリケーションを再デプロイします。
- C. SHA1 の代わりにMD5 ハッシュを使用してCLoakedServlet クラスを再コンパイルします。
Correct Answer: B
QUESTION 71
カスタマーサポートツールは、保持と分析のために、すべてのメールとチャットの会話をGoogle Cloud Bigtable に記録します。
個人を特定できる情報または支払いカード情報のデータを初期保存する前にササニタイズ(sanitize)するための推奨されるアプローチは何ですか?
- A. SHA256 を使用してすべてのデータをハッシュします。
- B. 楕円曲線暗号を使用してすべてのデータを暗号化します。
- C. Google Cloud Data Loss Prevention API を使用してデータの識別を解除します。
- D. 正規表現を使用して、電話番号、メールアドレス、クレジットカード番号を見つけて編集します。
Correct Answer: C
QUESTION 72
Google Cloud Shell を使用しており、数週間で使用するカスタムユーティリティをインストールする必要があります。
ファイルをデフォルトの実行パスに保存し、セッション間で保持するには、どこに保存しますか?
- A. ~/bin
- B. Google Cloud Storage
- C. /google/scripts
- D. /usr/local/bin
Correct Answer: A
QUESTION 73
Google Compute Engine インスタンスとオンプレミスのデータセンターの間にプライベート接続を作成します。
少なくとも20 Gbpsの接続が必要です。Google のベストプラクティスに従いまし
接続をどのように設定するべきでしょうか??
- A. VPCを作成し、Dedicated Interconnect を使用してオンプレミスのデータセンターに接続します。
- B. VPCを作成し、単一のGoogle Cloud VPN を使ってオンプレミスのデータセンターに接続します。
- C. Google Cloud Content Delivery Network(Google Cloud CDN)を作り、Dedicated Interconnect を使ってオンプレミスのデータセンターに接続します。
- D. Google Cloud CDN を作り、単一のGoogle Cloud VPN でオンプレミスのデータセンターに接続します。
Correct Answer: A
QUESTION 74
スタートアップが、GCP をを試験的に利用するためのビジネスプロセスを分析と定義していますが、製品に対する消費者の需要がどうなるかはまだわかりません。
マネージャーは、GCP サービスコストを最小限に抑え、Google のベストプラクティスに従うことを望んでいます。
何をするべきでしょうか?
- A. 無料枠と継続利用割引を利用し、サービスコスト管理のためのスタッフを配置します。
- B. 無料枠と継続利用割引を利用し、サービスコスト管理についてのトレーニングをチームに受けさせます。
- C. 無料枠と確定利用割引を利用し、サービスコスト管理のためのスタッフを配置します。
- D. 無料枠と確定利用割引を利用し、サービスコスト管理についてのトレーニングをチームに受けさせます。
Correct Answer: B
QUESTION 75
Git ソースリポジトリに格納されたプロジェクトの継続的デリバリー パイプラインを構築しており、コードの変更を検証して本番環境に展開できることを確認したいと考えています。
何をするべきでしょうか?
- A. Blue/Green(Red/Black)デプロイメントを使用して、Spinnaker を使用してビルドを運用環境に展開し、変更を簡単にロールバックできるようにします。
- B. Spinnaker を使用して、ビルドを運用環境に展開し、運用環境でテストを実行します。
- C. Jenkins を使用して、ステージング分岐とマスター分岐を構築します。完全なロールアウトを行う前に、10%のユーザーに対して本番環境への変更を構築および展開します。
- D. Jenkins を使用して、リポジトリ内のタグを監視します。テスト用にステージング環境にステージングタグを展開します。テスト後、リポジトリに本番用のタグを付け、本番環境に配備します。
Correct Answer: C
Reference:
– Lab: Build a Continuous Deployment Pipeline with Jenkins and Kubernetes
QUESTION 76
会社はオンプレミスのデータセンターをパブリック クラウドに移行しています。
移行の一環として、ワークロードオーケストレーション用にGoogle Kubernetes Engine(GKE)を統合し、アーキテクチャの一部もPCI DSSに準拠している必要があります。
どれが最も正確でしょうか?
- A. Google App Engineは、PCI DSS ホスティング用に認定されたGoogle Cloud Platform(GCP)上の唯一のコンピューティング プラットフォームです。
- B. GKE は、共有ホスティングと見なされるため、PCI DSS では使用できません。
- C. GKE とGCP は、PCI DSS 準拠の環境を構築するために必要なツールを提供します。
- D. GCP は、PCI 準拠として認定されているため、すべてのGoogle Cloud サービスが利用可能です。
Correct Answer: C
QUESTION 77
Google Cloud Platform リソースは、組織 / フォルダー / プロジェクトを使用して階層的に管理されます。
これらの異なるレベルにCloud Identity and Access Management(IAM)ポリシーが存在する場合、階層の特定のノードで有効なポリシーは何でしょうか?
- A. 有効なポリシーは、ノードで設定されたポリシーによってのみ決定されます。
- B. 有効なポリシーは、ノードで設定され、その祖先のポリシーによって制限されるポリシーです。
- C. 有効なポリシーは、ノードで設定されたポリシーと、その祖先から継承されたポリシーの和集合です。
- D. 有効なポリシーは、ノードで設定されたポリシーと、その祖先から継承されたポリシーの共通部分です。
Correct Answer: C
Reference:
– リソース階層
QUESTION 78
Google Compute Engine 上で動作するアプリケーションがあるとします。
災害復旧計画を考慮したアーキテクチャを設計する必要があります。
この計画では、地域で停止が発生した場合にアプリケーションを別の地域にフェイルオーバーする必要があります。
どうすればいいでしょうか?
- A. 同じプロジェクト内の異なる地域にある2つのGoogle Compute Engine インスタンスにアプリケーションをデプロイします。最初のインスタンスを使用してトラフィックを処理し、HTTP 負荷分散 サービスを使用して、災害の場合にスタンバイ インスタンスにフェールオーバーします。
- B. Google Compute Engine インスタンスにアプリケーションをデプロイします。インスタンスを使用してトラフィックを処理し、HTTP 負荷分散 サービスを使用して、災害発生時に社内のインスタンスにフェールオーバーします。
- C. 2つのGoogle Compute Engine インスタンス グループにアプリケーションをデプロイします。各グループは同じプロジェクト内にありますが、異なる地域にあります。最初のインスタンスグループを使用してトラフィックを処理し、HTTP 負荷分散 サービスを使用して、障害が発生した場合にスタンバイ インスタンス グループにフェールオーバーします。
- D. アプリケーションを2つのGoogle Compute Engine インスタンス グループにデプロイします。各グループは個別のプロジェクトと異なる地域にあります。最初のインスタンス グループを使用してトラフィックを処理し、HTTP 負荷分散 サービスを使用して、災害時にスタンバイ インスタンスにフェールオーバーします。
Correct Answer: C
QUESTION 79
社内データベースと統合する必要があるアプリケーションをGoogle App Engineにデプロイしています。
セキュリティ上の理由からオンプレミスのデータベースは、パブリック インターネット経由でアクセスできないようにする必要があります。
何をするべきでしょうか?
- A.アプリケーションをGoogle App Engine スタンダード環境にデプロイし、Google App Engine ファイアウォール ルールを使用して、開いているオンプレミスのデータベースへのアクセスを制限します。
- B.アプリケーションをGoogle App Engine スタンダード環境にデプロイし、Google Cloud VPN を使用してオンプレミスのデータベースへのアクセスを制限します。
- C. アプリケーションをGoogle App Engine フレキシブル環境にデプロイし、Google App Engine ファイアウォール ルールを使用して、オンプレミスデータベースへのアクセスを制限します。
- D. アプリケーションをGoogle App Engine フレキシブル環境にデプロイし、Google Cloud VPN を使用してオンプレミスのデータベースへのアクセスを制限します。
Correct Answer: D
QUESTION 80
Google Cloud Platafrom(GCP)でMicrosoft SQL Server をセットアップする必要があります。
管理では、GCP リージョン内のいずれかのゾーンでデータセンターが停止した場合にダウンタイムがないことが必要です。
何をするべきでしょうか?
- A. 高可用性を有効にしてGoogle Cloud SQL インスタンスを構成します。
- B. 地域インスタンス構成でGoogle Cloud Spanner インスタンスを構成します。
- C. Windows Server のフェールオーバー クラスタリングを使用したAlways On の可用性グループを使用して、Google Compute Engine でSQL Server をセットアップします。 ノードを異なるサブネットに配置します。
- D. Windows Server のフェールオーバー クラスタリングを使用して、SQL Server AlwaysOn の可用性グループを使用をセットアップします。 ノードを異なるゾーンに配置します。
Correct Answer: D
Reference:
– SQL Server AlwaysOn 可用性グループの構成
– SQL Server フェイルオーバー クラスタ インスタンスの構成
– Windows Server フェイルオーバー クラスタリングの実行
QUESTION 81
開発チームからKubernetes Deployment ファイルが提供されています。
インフラストラクチャはまだなく、アプリケーションを配備する必要があります。
どうすれば良いでしょうか?
- A. gcloud を使用してKubernetes クラスタを作成し、Google Cloud Deployment Manager を使用して、デプロイメントを作成します。
- B. gcloud を使用してKubernetes クラスタを作成し、kubectl を使用して展開を作成します。
- C. kubectl を使用してKubernetes クラスタを作成し、Google Cloud Deployment Managerを使用して、デプロイメントを作成します。
- D. kubectl を使用してKubernetes クラスタを作成し、 kubectlを使用して展開を作成します。
Correct Answer: B
QUESTION 82
新しいGoogle Cloud Platform(GCP)プロジェクトに対するチームの準備状況を評価する必要があります。
評価を実行し、コスト最適化のビジネス目標を組み込んだスキルギャップ計画を作成する必要があります。
チームはこれまでに2つのGCP プロジェクトを正常に展開しました。
何をするべきでしょうか?
- A.チームトレーニングに予算を割り当て、 新しいGCP プロジェクトの期限を設定します。
- B.チームトレーニングに予算を割り当て、チームのロードマップを作成して、職務に基づいてGoogle Cloud 認定資格を取得します。
- C. シニア外部コンサルタントを雇用するための予算を割り当て、新しいGCP プロジェクトの期限を設定します。
- D. シニア外部コンサルタントを雇用するための予算を割り当て、 チームのロードマップを作成して、職務に基づいてGoogle Cloud 認定資格を取得します。
Correct Answer: A
QUESTION 83
営業時間中にのみ使用するアプリケーションを設計しています。
実行可能製品リリースでは、アクティビティがないときにコストが発生しないように、自動的に「0にスケール」管理対象製品を使用する必要があります。
どのプライマリ コンピューティング リソースを選択するべきでしょか?
- A. Google Cloud Functions
- B. Google Compute Engine
- C. Google Kubernetes Engine
- D. Google AppEngine flexible environment
Correct Answer: A
QUESTION 84
オンプレミス環境からGoogle Cloud Storage にファイルをアップロードする必要があります。
お客様が提供する暗号鍵を使用して、Google Cloud Storage でファイルを暗号化する必要があります。
何をするべきでしょうか?
- A. Boto 構成ファイルで暗号鍵を提供します。gsutilを使用してファイルをアップロードします。
- B. gcloud config を使用して暗号鍵を提供します。gsutil を使用して、ファイルをそのバケットにアップロードします。
- C. gsutil を使用してファイルをアップロードし、フラグ–encryption-key を使用して暗号鍵を指定します。
- D. gsutil を使用してバケットを作成し、フラグ–encryption-key を使用して暗号鍵を指定します。gsutilを使用してファイルをそのバケットにアップロードします。
Correct Answer: A
Reference:
– Boto を使用する場合
– 顧客指定の暗号鍵
QUESTION 85
顧客は、Google Cloud Platform で実行されているゲームサーバーから複数のGBのリアルタイムの重要業績評価指標(KPI)をキャプチャし、低遅延でKPIを監視したいと考えています。
どのようにKPIを取得するべきでしょうか?
- A. ゲームサーバの時系列データをGoogle Bigtableに保存し、Google データポータル を使用して表示できます。
- B. ゲームサーバからカスタムメトリックをStackdriver に出力し、Stackdriver Monitoring Console でダッシュボードを作成して表示します。
- C. Google Cloud Storage に10分おきにアップロードされる分析ファイルを取り込むためにGoogle BigQuery がジョブをロードし、Google データポータル で結果を可視化するのをスケジュールする。
- D. KPIをGoogle Cloud Datastore エンティティに挿入して、アドホック分析を実行し、Google Cloud Datalab で視覚化します。
Correct Answer: A
Reference:
– データ ライフサイクル
QUESTION 86
単一のGoogle Cloud SQL インスタンスを使用して、特定のゾーンからアプリケーションを提供しており、高可用性を導入する必要があります。
どうすれば良いでしょうか?
- A. 異なるリージョンにリードレプリカのインスタンスを作成します。
- B. 別のリージョンにフェイルオーバーのレプリカインスタンスを作成します。
- C. 同じリージョンで異なるゾーンにリードレプリカのインスタンスを作成します。
- D. 同じリージョンで異なるゾーンにフェイルオーバーのレプリカインスタンスを作成します。
Correct Answer: D
Reference:
– 高可用性構成の概要
– レプリカの管理
QUESTION 87
Webアプリケーションには、VPC 内で実行されている複数のVMインスタンスがあります。
インスタンス間の通信を許可するパスとポートのみに制限したいですが、アプリが自動スケーリングできるため、静的IPアドレスやサブネットに依存したくありません。
どのように通信を制限すれば良いでしょうか?
- A.個別のVPC を使用して、トラフィックを制限します。
- B. コンピューティング インスタンスにアタッチされたネットワーク タグに基づくファイアウォール ルールを使用します。
- C. Google Cloud DNS を使用し、許可されたホスト名からの接続のみを許可します。
- D. サービスアカウント を使用し、特定のサービス アカウントにアクセスを許可するようにWebアプリケーションを構成します。
Correct Answer: B
QUESTION 88
大規模なCRM 展開のデータベース バックエンドとしてGoogle Cloud SQL を使用しています。
使用量の増加に合わせて拡張し、ストレージが不足しないように、CPU 使用率コアを75 %に維持し、レプリケーションのラグを60 秒未満に抑える必要があります。
要件を満たすための正しい手順は何でしょうか?
- A.
- インスタンスの自動ストレージ増加を有効にします。
- CPU 使用率が75 %を超えた場合にStackdriver アラートを作成し、インスタンスタイプを変更してCPU 使用率を削減します。
- レプリケーション ラグのStackdriver アラートを作成し、データベースを分割してレプリケーション時間を短縮します。
- B.
- インスタンスの自動ストレージ増加を有効にします。
- インスタンスタイプを32コア マシンタイプに変更して、CPU 使用率を75 %未満に保ちます。
- レプリケーション ラグのStackdriver アラートを作成し、memcache を展開して、マスターの負荷を軽減します。
- C.
- ストレージが75 %を超えたときにStackdriver アラートを作成し、インスタンスで使用可能なストレージを増やして、より多くのスペースを作成します。
- memcached をデプロイして、CPU 負荷を減らします。
- インスタンスタイプを32コア マシンタイプに変更して、レプリケーション ラグを減らします。
- D.
- ストレージが75 %を超えたときにStackdriver アラートを作成し、インスタンスで使用可能なストレージを増やして、より多くのスペースを作成します。
- memcached をデプロイして、CPU 負荷を減らします。
- レプリケーション ラグのStackdriverアラートを作成し、インスタンスタイプを32コア マシンタイプに変更して、レプリケーション ラグを減らします。
Correct Answer: A
QUESTION 89
すでにアプリケーションをGoogle Kubernetes Engine(GKE)にデプロイし、Google Cloud SQL Proxy コンテナを使用し、Kubernetes で実行されているサービスでGoogle Cloud SQL データベースを利用可能にしています。
アプリケーションがデータベース接続の問題を報告していることが通知されており、会社のポリシーには事後分析が必要です。
何をするべきでしょうか?
- A. gcloud sqlインスタンスの再起動を使用します。
- B. Google Cloud SQL Proxy コンテナが使用するサービス アカウントにCloud Build Editor の役割がまだあることを検証します。
- C. GCP Console でStackdriver Logging に移動します。GKEやGoogle Cloud SQL のログを参照してください。
- D. GCP Console でGoogle Cloud SQL に移動します。最新のバックアップを復元します。kubectl を使用してすべてのポッドを再起動します。
Correct Answer: C
QUESTION 90
アプリケーションは、分析のためにログをGoogle BigQuery に書き込むことになります。
各アプリケーションには、独自のテーブルが必要で、45日を経過したログはすべて削除する必要があります。
ストレージを最適化し、Google のベストプラクティスに従います。
どうすれば良いでしょうか?
- A. テーブルの有効期限を45 日に設定します。
- B. テーブルをタイムパーティション化し、パーティションの有効期限を45 日に設定します。
- C. Google BigQuery のデフォルトの振る舞いを利用して、45 日以上経過したアプリケーションログを削除する。
- D. Google BigQuery コマンドライン ツール(bg)を使用して、45 日より古いレコードを削除するスクリプトを作成する。
Correct Answer: B
Reference:
– パーティション分割テーブルの管理
– BigQuery のおすすめの方法: ストレージの最適化
QUESTION 91
Google Kubernetes Engine クラスタで、CPU 負荷に基づいてノードを自動的に追加または削除する必要があります。
何をするべきでしょうか?
- A. ターゲット CPU 使用率でHorizontalPodAutoscaler(HPA)を構成します。GCP Consoleからクラスタ オートスケーラーを有効にします。
- B. ターゲット CPU 使用率でHorizontalPodAutoscaler(HPA)を構成します。gcloud コマンドを使用して、クラスターのマネージド インスタンス グループで自動スケーリングを有効にします。
- C. デプロイメントを作成し、maxUnavailable およびmaxSurge プロパティを設定します。gcloud コマンドを使用して、クラスタ オートスケーラーを有効にします。
- D. デプロイメントを作成し、maxUnavailable およびmaxSurge プロパティを設定します。 GCP Console からクラスタのマネージド インスタンス グループで自動スケーリングを有効にします。
Correct Answer: A
QUESTION 92
会社は全国的に運営されており、タイムクリティカルではないものを含む複数のバッチ ワークロードにGoogle Cloud Platafrom(GCP)を使用する予定です。
HIPAA 認定のGCP サービスを使用し、サービスコストを管理する必要もあります。
Google ベストプラクティスを満たすためにどのように設計する必要がありますか?
- A. プリエンプティブル VMをプロビジョニングしてコストを削減し、HIPAA に準拠していないすべてのGCP サービスとAPI の使用を中止します。
- B. プリエンプティブル VMをプロビジョニングして、コストを削減し、HIPAA に準拠していないすべてのGCP サービスとAPI の使用を無効にしてから使用を停止します。
- C. コストを削減するために同じリージョンに標準 VMをプロビジョニングし、 HIPAA に準拠していないすべてのGCP サービスとAPI の使用を中止します。
- D. 標準 VMを同じリージョンにプロビジョニングしてコストを削減し、HIPAA に準拠していないすべてのGCP サービスとAPI の使用を無効にしてから使用を停止します。
Correct Answer: B
Reference:
– Google Cloud Platform での HIPAA コンプライアンス
– HIPAA 対応プロジェクトの設定
– アーキテクチャ: HIPAA 対応の Cloud Healthcare
QUESTION 93
顧客は、認証レイヤーの耐障害性テストを希望しています。
Google Cloud SQL インスタンスの読み取りと書き込みを行う公開 REST API を提供するリージョン マネージド インスタンス グループで構成されます。
何をするべきでしょうか?
- A. セキュリティ企業と協力して、悪意のあるWebサイトからユーザの認証データを検索します。見つかった場合は通知するWebスクレイパーを実行します。
- B. 不正アクセスを検出してログに記録するために、仮想マシンに侵入検知ソフトウェアを導入します。
- C. ゾーン内のすべてのVMをシャットダウンしてアプリケーションの動作を確認できる災害シミュレーションの実行をスケジュールします。
- D. マスターとは別のゾーンでGoogle Cloud SQL インスタンスの読み取りレプリカを設定し、REST API のKPI を監視しながら手動でフェイルオーバーをトリガーします。
Correct Answer: C
QUESTION 94
マネージド インスタンス グループの作成を自動化したいと考えています。
VMには、多くのOS パッケージの依存関係があり、インスタンス グループ内の新しいVMの起動時間を最小限にしたいと望んでいます。
何をするべきでしょうか?
- A. Terraform を使用して、マネージド インスタンス グループと起動スクリプトを作成し、OS パッケージの依存関係をインストールします。
- B. すべてのOSパッケージの依存関係を持つカスタムVM イメージを作成します。 Google Cloud Deployment Manager を使用して、VM イメージでマネージド インスタンス グループを作成します。
- C. Puppet を使用して、マネージドインスタンスグループを作成し、OSパッケージの依存関係をインストールします。
- D. Google Cloud Deployment Manager を使用してマネージド インスタンス グループを作成し、Ansible でOS パッケージの依存関係をインストールします。
Correct Answer: B
QUESTION 95
アーキテクチャでは、プロジェクト内のすべての管理アクティビティとVM システムログを集中的に収集する必要があります。
これらのログをVMとサービスの両方からどのように収集する必要がありますか?
- A.すべての管理およびVM システムログは、Stackdriver によって自動的に収集されます。
- B. Stackdriver は、ほとんどのサービスの管理アクティビティログを自動的に収集します。システムログを収集するには、Stackdriver Logging エージェントを各インスタンスにインストールする必要があります。
- C. カスタム syslogd VMを起動し、GCP プロジェクトとVMを設定して、すべてのログをそこに転送します。
- D. Stackdriver Logging エージェントを単一のVMにインストールし、環境のすべての監査ログとアクセスログを収集します。
Correct Answer: B
QUESTION 96
Google App Engine アプリケーションを更新する必要があります。
現在のアプリケーションバージョンを置き換える前に、運用トラフィックで更新をテストします。
どうすれば良いでしょうか?
- A. インスタンス グループ アップデータを使用して、部分ロールアウトを作成してカナリアテストを可能にします。
- B. Google App Engine アプリケーションで更新を新しいバージョンとして展開し、トラフィックを新しいバージョンと現在のバージョンに分割します。
- C. アップデートを新しいVPCにデプロイし、Google のグローバル HTTPロードバランシングを使用して、アップデートと現在のアプリケーション間でトラフィックを分割します。
- D. 更新プログラムを新しいGoogle App Engineアプリケーションとして展開し、Googleのグローバル HTTP 負荷分散を使用して、新しいアプリケーションと現在のアプリケーションの間でトラフィックを分割します。
Correct Answer: B
QUESTION 97
顧客は、eコマースサイトで使用されるWebサービスを実行して、製品の推奨事項をユーザーに提供します。
結果の品質を改善するために、Google Cloud Platform で機械学習モデルの実験を開始しました。
時間の経過とともにモデルの結果を改善するために、顧客は何をすべきでしょうか?
- A. Google Cloud Machine Learning Engine のパフォーマンスメトリックをStackdriver からGoogle BigQuery にエクスポートし、モデルの効率性を分析します。
- B. 機械学習モデルのトレーニングをGoogle Cloud GPU からGoogle Cloud TPU に移行するためのロードマップを作って、結果を改善します。
- C. Google Compute Engine のアナウンスを監視して、新しいCPU アーキテクチャが利用できるかどうかを調べ、パフォーマンスを向上するようになったら、すぐにアーキテクチャにモデルをデプロイします。
- D.推奨事項の履歴と推奨事項の結果をGoogle BigQuery に保存し、トレーニングデータとして使用します。
Correct Answer: D
QUESTION 98
会社の開発チームが、Docker化されたHTTPS Webアプリケーションを作成しました。
Google Kubernetes Engine(GKE)にアプリケーションをデプロイし、アプリケーションが自動的にスケーリングすることを確認する必要があります。
GKE は、どのようにデプロイするのが良いでしょうか?
- A. 水平ポッド自動スケーリングを使用して、クラスタの自動スケーリングを有効にします。Ingress リソースを使用して、HTTPS トラフィックを負荷分散します。
- B. 水平ポッド自動スケーリングを使用して、Kubernetes クラスタでクラスタの自動スケーリングを有効にします。LoadBalancer タイプのサービスリソースを使用してHTTPS トラフィックを負荷分散します。
- C. Google Compute Engine インスタンス グループで自動スケーリングを有効にします。Ingress リソースを使用して、HTTPS トラフィックを負荷分散します。
- D. Google Compute Engine インスタンス グループで自動スケーリングを有効にします。LoadBalancer タイプのサービスリソースを使用してHTTPS トラフィックを負荷分散します。
Correct Answer: B
Reference:
– クラスタの自動スケーリング
QUESTION 99
会社は、ユーザが会社のWebサイトからダウンロードできるレンダリングソフトウェアを作成します。
会社には世界中に顧客がおり、すべてのお客様の遅延を最小限に抑える必要があります。
Google のベストプラクティスに従います。
ファイルはどのように保存しますか?
- A. Google Cloud Multi-Regional Storageバケットにファイルを保存します。
- B. Google Cloud Regional Storage バケットにファイルを保存します。リージョンのゾーンごとに1つのバケットがあります。
- C. ファイルを複数のGoogle Cloud Regional Storage バケットに保存します。リージョンごとにゾーンごとに1つのバケットがあります。
- D. ファイルを複数のGoogle Cloud Multi-Regional Storage バケットに保存します(Multi-Regionalごとに1つのバケット)。
Correct Answer: A
QUESTION 100
会社は、ヘルスケアのスタートアップを買収し、顧客の医療情報を、それが作成された時期に応じて、最大4年間保持する必要があります。
企業のポリシーでは、このデータを安全に保持し、規制が許可されたらすぐに削除します。
どの手段を取るべきでしょうか?
- A.データをGoogle ドライブに保存し、有効期限が切れたら手動でレコードを削除します。
- B. Google Cloud Data Loss Prevention API を使用してデータを匿名化し、無期限に保存します。
- C. Google Cloud Storage にデータを保存し、ライフサイクル管理を使用して、有効期限が切れたファイルを削除します。
- D. データをGoogle Cloud Storage に保存し、期限切れのデータをすべて削除する夜間のバッチスクリプトを実行します。
Correct Answer: C
Comments are closed