
※ 他の問題集は「タグ:Professional Data Engineer の模擬問題集」から一覧いただけます。
この模擬問題集は「Professional Data Engineer Practice Exam (2021.03.04)」の回答・参考リンクを改定した日本語版の模擬問題集です。
Google Cloud 認定資格 – Professional Data Engineer – 模擬問題集(全 50問)
Question 1
ウェブアプリケーションのログを含むトピックを持つApache Kafka クラスタをオンプレミスで使用しています。
Google BigQuery とGoogle Cloud Storage で分析するために Google Cloud に複製する必要があります。推奨されるレプリケーション方法はKafka Connect プラグインのデプロイを避けるためのミラーリングです。
どうすればいいのでしょうか?
- A. Google Compute Engine VM インスタンスでKafka クラスタを配置します。Google Compute Engine で実行されているクラスタにトピックをミラーリングするようにオンプレミスクラスタを構成します。Google Cloud Dataproc クラスタまたは Google Cloud Dataflow ジョブを使用してKafka からの読み取りと Google Cloud Storage に書き込みます。
- B. Google Cloud Pub/Sub Kafka コネクタをシンク コネクタとして構成した Google Compute Engine VM インスタンスでKafka クラスタをデプロイします。Google Cloud Dataproc クラスタまたは Google Cloud Dataflow ジョブを使用してKafka からの読み取りと Google Cloud Storage に書き込みます。
- C. Google Cloud Pub/Sub Kafka コネクタをオンプレミスのKafka クラスタに配置して Google Cloud Pub/Sub をソースコネクタとして構成します。Google Cloud Dataflow ジョブを使用して Google Cloud Pub/Sub から読み取り、Google Cloud Storage に書き込みます。
- D. Google Cloud Pub/Sub Kafka コネクタをオンプレミスの Kafka クラスタに配置して Google Cloud Pub/Sub をシンクコネクタとして構成します。Google Cloud Dataflow ジョブを使用して Google Cloud Pub/Sub からの読み取りと Google Cloud Storage に書き込みます。
Correct Answer: D
Question 2
Google BigQuery、Google Cloud Dataflow、Google Cloud Dataproc で実行されているデータ パイプラインがあります。
ヘルスチェックを実行してその動作を監視し、パイプラインが失敗した場合はパイプラインを管理するチームに通知する必要があります。また、複数のプロジェクト間で作業できる必要があり、プラットフォームのマネージド サービスを使用することが推奨されています。
何をすべきでしょうか?
- A. Google Stackdriver に情報をエクスポートしてアラート ポリシーを設定します。
- B. Google Compute Engine で仮想マシンをAirflow で実行して Google Stackdriver に情報をエクスポートします。
- C. ログを Google BigQuery にエクスポートし、Google App Engine でその情報を読み取り、ログで障害が見つかった場合にメールを送信するように設定します。
- D. Google Cloud API 呼び出しを使用してログを消費する Google App Engine アプリケーションを開発し、ログで障害を発見した場合にメールを送信します。
Correct Answer: A
Question 3
3つのデータ処理ジョブを開発しました。
1つ目は Google Cloud Dataflow パイプラインを実行して Google Cloud Storage にアップロードされたデータを変換し、Google BigQuery に結果を書き込みます。
2つ目はオンプレミス サーバーからデータを取り込み、それを Google Cloud Storage にアップロードします。
3つ目はサードパーティのデータプロバイダーから情報を取得し、その情報を Google Cloud Storage にアップロードする Google Cloud Dataflow パイプラインです。
これら 3つのワークフローの実行をスケジュールおよび監視し、必要に応じて手動で実行できる必要があります。
何をするべきかでしょうか?
- A. Google Cloud Composer で直接非周期グラフを作成し、ジョブをスケジュールして監視します。
- B. Stackdriver Monitoring を使用してジョブをトリガーするWebhook 通知付きのアラートを設定します。
- C. GCP API呼び出しを使用してジョブのステータスをスケジュールし、リクエストする Google App Engine アプリケーションを開発します。
- D. Google Compute Engine インスタンスに cron ジョブを設定して GCP API 呼び出しを使用してパイプラインをスケジュールして監視します。
Correct Answer: A
Question 4
Firebase Analytics とGoogle BigQuery の連携を有効にしました。
Firebase は Google BigQuery に app_events_YYYYMMDD の形式で新しいテーブルを毎日自動的に作成するようになりました。従来のSQL で過去 30日間のすべてのテーブルをクエリしたいとします。
どうすればいいのでしょうか?
- A. TABLE_DATE_RANGE function を使用します。
- B. WHERE_PARTITIONTIME pseudo column を使用します。
- C. WHERE date BETWEEN YYYY-MM-DD AND YYYY-MM-DD を使用します。
- D. SELECT IF.(date >= YYYY-MM-DD AND date <= YYYY-MM-DD を使用します。
Correct Answer: A
Reference contents:
– Using BigQuery and Firebase Analytics to understand your mobile app
– BigQuery と Firebase Analytics でモバイルアプリを理解する
– レガシー SQL 関数と演算子 #構文 | BigQuery
Question 5
Google Cloud Pub/Sub サブスクリプションをソースとして実行している Google Cloud Dataflow ストリーミング パイプラインがあります。
新しい Google Cloud Dataflow パイプラインを現在のバージョンと互換性のないものにするコードを更新する必要があります。この更新を行うときにデータ紛失を避けなければなりません。
どうすればいいのでしょうか?
- A. 現在のパイプラインを更新してドレイン フラグを使用します。
- B. 現在のパイプラインを更新して変換マッピングのJSON オブジェクトを提供します。
- C. 同じ Google Cloud Pub/Sub サブスクリプションを持つ新しいパイプラインを作成し、古いパイプラインをキャンセルします。
- D. 新しい Google Cloud Pub/Sub サブスクリプションを持つ新しいパイプラインを作成し、古いパイプラインをキャンセルします。
Correct Answer: D
Question 6
Node.js で記述された Google Cloud Functions を使用して Google Cloud Pub/Sub からメッセージを引き出し、そのデータを Google BigQuery に送信しています。
Google Cloud Pub/Sub トピックのメッセージ処理率が予想よりも桁違いに高いことが分かりましたが Stackdriver ログビューアにはエラーが記録されていません。
この問題の最も可能性の高い原因は何でしょうか?(回答を 2つ選択してください)
- A. パブリッシャーのスループットクォータが小さすぎます。
- B. 未処理のメッセージの合計が最大 10 MB を超えています。
- C. サブスクライバーのコードでのエラー処理が実行時エラーを適切に処理していません。
- D. サブスクライバーのコードがメッセージに追いつくことができません。
- E. サブスクライバーのコードは Pull するメッセージを確認しません。
Correct Answer: C、E
Question 7
Google BigQuery には過去 3年間の履歴データと新しいデータを Google BigQuery に毎日配信するデータパイプラインがあります。
データサイエンス チームが日付列にフィルタリングされたクエリを実行し、30 〜 90 日分のデータに限定した場合、クエリがテーブル全体をスキャンすることに気が付きました。また請求書が予想以上に早く増加していることにも気付きました。SQL クエリを実行する能力を維持しながら、できるだけコスト効率よく問題を解決したいと考えています。
どうすればよいでしょうか?
- A. DDL を使用してテーブルを再作成します。TIMESTAMP またはDATE タイプを含む列でテーブルを分割します。
- B. データサイエンスチームにテーブルを Google Cloud Storage のCSV ファイルにエクスポートし、Google Cloud Datalab を使用してファイルを直接読み込んでデータを探索することをお勧めします。
- C. パイプラインを修正して直近の 30 ~ 90 日分のデータを 1つのテーブルにより長い履歴を別のテーブルに保持し、履歴全体にわたるテーブルのフルスキャンを最小限に抑えるようにします。
- D. 1日あたり Google BigQuery テーブルを作成するApache Beam パイプラインを作成します。データサイエンスチームが必要なデータを選択するために、テーブル名のサフィックスにワイルドカードを使用することをお勧めします。
Correct Answer: A
Question 8
Google Cloud Dataproc クラスタでスケジュール上で実行される複数のSpark ジョブがあります。
いくつかのジョブは順番に実行され、いくつかのジョブは同時に実行されます。このプロセスを自動化する必要があります。
どうすればよいでしょうか?
- A. Google Cloud Dataproc ワークフロー テンプレートを作成します。
- B. ジョブを実行するための初期化アクションを作成します。
- C. Google Cloud Composer で有向非巡回グラフを作成します。
- D. Google Cloud SDK を使用してクラスタを作成してジョブを実行し、クラスタを破棄するためのBash スクリプトを作成します。
Correct Answer: A
Reference contents:
– ワークフローの使用 | Dataproc ドキュメント
– Dataproc ワークフロー テンプレートの概要 | Dataproc ドキュメント
Question 9
下の図に示すいくつかのデータがあります。
2つの次元はXとYであり、各ドットの陰影はそれがどのクラスであるかを表します。 線形アルゴリズムを使用してこのデータを正確に分類するためには合成特徴量を追加する必要があります。
その特徴量の値はどのようにしたらよいでしょうか?
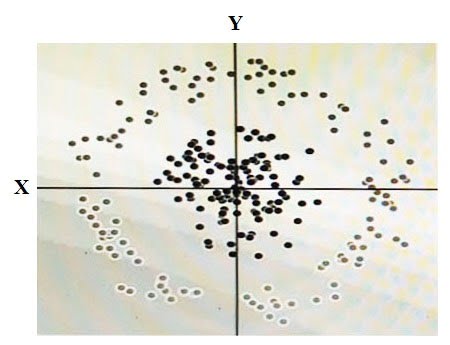
- A. X^2+Y^2
- B. X^2
- C. Y^2
- D. cos(X)
Correct Answer: A
Question 10
CSV ファイルから Google BigQuery テーブル のCLICK_STREAM にデータを読み込むのに数日かかりました。
DataTable 列にはクリックイベントのエポック時間が格納されます。 便宜上、すべてのフィールドがSTRING 型として扱われる単純なスキーマを選択しました。 ここでサイトにアクセスするユーザーのWeb セッション期間を計算し、そのデータ型をTIMESTAMP に変更して 将来のクエリの計算コストをかけずに移行作業を最小限に抑えたいと考えています。
何をするべきかでしょうか?
- A. CLICK_STREAM テーブルを削除してDataTable 列が TIMESTAMP 型になるようにテーブルを再作成してデータを再読み込みします。
- B. CLICK_STREAM テーブルにTIMESTAMP の列にTIMESTAMP を追加し、各行のTIMESTAMP 列から数値を入力します。今後はDataTable 列ではなくTIMESTAMP 列を参照します。
- C. CLICK_STREAM_V ビューを作成してDataTable 列からの文字列をTIMESTAMP 値にキャストします。今後はCLICK_STREAM テーブルの代わりにCLICK_STREAM_V ビューを参照します。
- D. CLICK STREAM テーブルに 2つの列を追加します。TIMESTAMP 型のTIMESTAMP と BOOLEAN 型のIS_NEW です。追加モードですべてのデータを再読み込みします。追加された行ごとにIS_NEW の値をtrue に設定します。今後のクエリはDataTable 列の代わりにTIMESTAMP 列を参照し、WHERE句でIS_NEW の値がtrue でなければならないようにします。
- E. 組込み関数を使用してDataTable 列からの文字列をTIMESTAMP 値にキャストしながら、CLICK_STREAM テーブルの全行を返すクエリを構築します。TIMESTAMP 列がTIMESTAMP タイプの宛先をNEW_CLICK_STREAM テーブルに対してクエリを実行します。今後はCLICK_STREAM テーブルではなく、NEW_CLICK_STREAM テーブルを参照します。将来的には新しいデータがNEW_CLICK_STREAM テーブルに再読み込みされます。
Correct Answer: E
Reference contents:
– テーブル スキーマの手動変更 #列のデータ型の変更 | BigQuery
Question 11
約 3年前に新しいゲームアプリを立ち上げました。
前日のログファイルを「LOGS_yyyymmdd」というテーブル名のフォーマットで別の Google BigQuery テーブルにアップロードしています。
テーブルのワイルドカード関数を使用してすべての時間範囲の日次および月次レポートを生成しています。最近、長い日付範囲をカバーする一部のクエリが 1,000 テーブルの制限を超えて失敗していることがわかりました。
この問題を解決するにはどうすればよいでしょうか?
- A. すべての日次ログテーブルを日付分割テーブルに変換します。
- B. シャードされたテーブルを単一の分割テーブルに変換します。
- C. クエリ キャッシュを有効にして前月のデータをキャッシュできるようにします。
- D. 毎月カバーする個別のビューを作成してこれらのビューからクエリを実行します。
Correct Answer: A
Question 12
次の要件を持つ新規プロジェクトのデータベースを選択する必要があります。
– フル マネージド サービス
– 自動スケールアップが可能
– トランザクション的に一貫性がある
– 最大 6 TBまで拡張可能
– SQL を使用してクエリを実行可能
どのデータベースを選ぶべきでしょうか?
- A. Google Cloud SQL
- B. Google Cloud Bigtable
- C. Google Cloud Spanner
- D. Google Cloud Datastore
Correct Answer: A
Question 13
何百万台ものコンピュータの時系列のCPU とメモリ使用量を格納するデータベースを選択する必要があります。
アナリストはデータベースに対してリアルタイムでアドホックな分析を行うためにデータを1秒間隔のサンプルで保存する必要があります。実行クエリごとに課金されることを避けるためにスキーマ設計がデータセットが拡張可能にしておきます。
どのデータベースとデータモデルを選択すべきでしょうか?
- A. Google BigQuery でテーブルを作成してCPU とメモリの新しいサンプルをテーブルに追加します。
- B. Google BigQuery で幅の広いテーブルを作成して各秒のサンプル値の列を作成し、毎秒の間隔で行を更新します。
- C. Google Cloud Bigtable で幅の狭いテーブルを作成し、Google Computer Engine コンピュータ識別子と各秒のサンプル時間を組み合わせた行キーを使用して、行を更新します。
- D. Google Cloud Bigtable にコンピュータ識別子と毎分 サンプルタイムを組み合わせた行キーで幅の広いテーブルを作成し、毎秒 値を列データとして組み合わせます。
Correct Answer: C
Reference contents:
– 時系列データ用のスキーマ設計 #行キー設計のパターン | Cloud Bigtable ドキュメント
Question 14
次の要件で運用チーム向けの可視化を構成する必要があります。
– テレメトリーには直近 6 週間分の 50,000 施設すべてのデータが含まれている必要があります(毎分サンプリング)。
– レポートはライブデータから 3時間以上遅れてはいけません。
– 実行可能なレポートは最適でないリンクのみを表示すること。
– ほとんどの最適でないリンクは一番上にソートされるべきです。
– 最適でないリンクは、地域別にグループ化してフィルタリングすることができます。
– レポートを読み込みするためのユーザーの応答時間は 5 秒未満でなければなりません。
直近 6 週間のデータを保存するデータソースを作成し、複数の日付範囲、異なる地理的地域、および固有のインストールタイプを表示できるようにビジュアライゼーションを作成します。ビジュアライゼーションに変更を加えることなく、常に最新のデータを表示します。毎月新しいビジュアライゼーションを作成して更新することを避けたいと考えています。
どうすればよいのでしょうか?
- A. 現在のデータを調べて基準の可能な組み合わせごとに 1つずつ、一連のチャートと表を作成します。
- B. 現在のデータを調べて値の選択を可能にする基準フィルターにバインドされた一般化されたチャートとテーブルの小さなセットを作成します。
- C. データをスプレッドシートにエクスポートして一連のチャートと表を作成し、可能な基準の組み合わせごとに 1つずつ作成し、複数のタブに分散させます。
- D. リレーショナル データベースのテーブルにデータを読み込みし、すべての行をクエリし、各基準のデータを要約し、Google チャートと可視化 API を使用して結果を表示する Google App Engine アプリケーションを作成します。
Correct Answer: B
Question 15
次の要件で運用チーム向けのビジュアライゼーションを構成する必要があります。
– レポートには直近6週間(1分に1回サンプリング)の全 50,000 施設からの遠隔測定データを含める必要があります。
– レポートは、ライブデータから3時間以上遅れてはいけません。
– 実行可能なレポートは、最適でないリンクのみを表示する必要があります。
– ほとんどの最適でないリンクは、一番上にソートされるべきです。
– 最適でないリンクは、地域別にグループ化してフィルタリングすることができます。
– レポートを読み込みするためのユーザーの応答時間は5秒未満でなければなりません。
どのアプローチが要件を満たしていますか?
- A. データを Google スプレッドシートに読み込み、数式を使用して指標を計算し、フィルタ/並べ替えを使用してテーブルに最適ではないリンクのみを表示します。
- B. データを Google BigQuery テーブルに読み込み、データをクエリし、メトリックを計算して Google スプレッドシートのテーブルに最適ではない行のみを表示する Google AppsScript を記述します。
- C. データを Google Cloud Datastore のテーブルに読み込みし、すべての行をクエリし、メトリックを導出する関数を適用し、Google チャートおよび可視化 API を使用して結果を表に表示する Google App Engine アプリケーションを記述します。
- D. データを Google BigQuery テーブルに読み込み、データに接続して指標を計算してフィルタ式を使用してテーブル内の最適ではない行のみを表示する Google Data Studio 360 レポートを作成します。
Correct Answer: D
Question 16
リレーショナル データベースから数百万件の機密性の高い患者記録を Google BigQuery にコピーする必要があります。
データベースの合計サイズは 10 TBです。安全で時間効率の良いソリューションを設計する必要があります。
何をすべきでしょうか?
- A. データベースからレコードをAvro ファイルとしてエクスポートします。gsutil を使用して Google Cloud Storage にファイルをアップロードし、Google Cloud コンソールの Google BigQuery を使用して Avro ファイルを Google BigQuery に読み込みます。
- B. データベースからレコードをAvro ファイルとしてエクスポートします。このファイルを Google Transfer Appliance にコピーして Google に送信し、Google Cloud コンソールの Google BigQuery を使用してAvroファイルを Google BigQuery に読み込みます。
- C. データベースからレコードをCSV ファイルにエクスポートします。CSV ファイルの公開 URL を作成し、Google Cloud Storage Transfer Service を使用して Google Cloud Storage にファイルを移動します。Google Cloud コンソールのGoogle BigQuery Web UIを使用してCSV ファイルを Google BigQuery に読み込みます。
- D. データベースからレコードをAvro ファイルとしてエクスポートします。Avro ファイルの公開 URL を作成し、Google Cloud Storage Transfer Service を使用して Google Cloud Storage にファイルを移動します。Google Cloud コンソールの Google BigQuery を使用してAvro ファイルを Google BigQuery に読み込みます。
Correct Answer: A
Question 17
時系列のトランザクション データをコピーするデータ パイプラインを作成してデータ サイエンス チームが分析のために Google BigQuery 内からクエリできるようにする必要があります。
1 時間ごとに数千件のトランザクションが新しいステータスで更新されます。初期のデータセットのサイズは 1.5 PBで 1日あたり 3 TBずつ増えていきます。データは重く構造化されており、データサイエンスチームはこのデータに基づいて機械学習モデルを構築します。データサイエンスチームのパフォーマンスとユーザビリティを最大化したいと考えています。
どの戦略を採用すべきでしょうか?(回答を 2つ選択してください)
- A. データをできるだけ非正規化します。
- B. データの構造を可能な限り保持します。
- C. Google BigQuery UPDATE を使用してデータセットのサイズをさらに小さくします
- D. ステータスの更新が更新されるのではなく、Google BigQuery に追加されるデータパイプラインを開発します。
- E. トランザクション データの毎日のスナップショットを Google Cloud Storage にコピーし、Avro ファイルとして保存します。Google BigQuery の外部データ ソースのサポートを使用してクエリを実行します。
Correct Answer: A、D
Reference contents:
– データ ウェアハウス使用者のための BigQuery #変更の処理 | ソリューション | Google Cloud
Question 18
Google BigQuery データ ウェアハウス内の主な在庫テーブルを読み取るリアルタイムのインベントリ ダッシュボードを作成する必要があります。
過去のインベントリ データはアイテム別、場所別のインベントリ残高として保存されます。1 時間ごとに数千件のインベントリの更新があります。ダッシュボードのパフォーマンスを最大化し、データが正確であることを確認したいと考えています。
どうすればいいのでしょうか?
- A. Google BigQuery UPDATE ステートメントを活用してインベントリ残高の変化に合わせて更新します。
- B. 各インベントリの更新でスキャンされるデータ量を減らすために項目ごとにインベントリ残高テーブルを分割します。
- C. Google BigQuery を使用して毎日のインベントリ移動テーブルにストリーム変更をストリーミングします。履歴のインベントリ残高表に結合するビューで残高を計算します。インベントリ残高テーブルを毎晩更新します。
- D. Google BigQuery バルク ローダーを使用してインベントリの変更を毎日のインベントリ移動テーブルにバッチロードします。履歴のインベントリ残高テーブルに結合するビューで残高を計算し、インベントリ残高テーブルを毎晩更新します。
Correct Answer: C
Reference contents:
– Google Cloud ブログ:BigQuery 特集: データの取り込み
Question 19
Google Cloud Spanner で商品の販売データを保存する新しいトランザクション テーブルを作成する必要があります。
プライマリキーとして何を使用するかを決めています。
パフォーマンスの観点からどちらの戦略を選択すべきでしょうか?
- A. 現在のエポック時刻
- B. ランダムなユニバーサル 一意識別子番号(バージョン4 UUID)
- C. 製品名と現在のエポック時刻の連結
- D. 単調に増加する整数である、販売システムからの元の注文識別番号。
Correct Answer: B
Reference contents:
– Online UUID Generator Tool
– スキーマとデータモデル #主キーの選択 | Cloud Spanner
Question 20
既存の初期化アクションを使用して起動時にすべての Google Cloud Dataproc クラスタに追加の依存関係をデプロイする必要があります。
会社のセキュリティポリシーでは Google Cloud Dataproc ノードがインターネットにアクセスできないため、パブリック初期化アクションでリソースを取得できないようする必要があります。
何をするべきでしょうか?
- A. Google Cloud SQL Proxy を Google Cloud Dataproc マスターにデプロイします。
- B. SSH トンネルを使用して Google Cloud Dataproc クラスタがインターネットにアクセスできるようにします。
- C. すべての依存関係を VPC セキュリティ境界内の Google Cloud Storage バケットにコピーします。
- D. Google Cloud Resource Manager を使用して Google Cloud Dataproc クラスタが使用するサービス アカウントを Network User ロールに追加します。
Correct Answer: C
Reference contents:
– 初期化アクション | Dataproc ドキュメント
– Dataproc クラスタ ネットワークの構成 #内部 IP アドレスのみで Dataproc クラスタを作成する | Dataproc ドキュメント
Question 21
2 TBのリレーショナル データベースを Google Cloud Platform に移行する必要があります。
このデータベースを使用するアプリケーションを大幅にリファクタリングするためのリソースを持っておらず、運用コストが主な懸念事項です。
データの保存と提供にはどのサービスを選択するべきでしょうか?
- A. Google Cloud Spanner
- B. Google Cloud Bigtable
- C. Firestore
- D. Google Cloud SQL
Correct Answer: D
Question 22
6 ヶ月以内に 2 PB の履歴データをオンプレミスのストレージ アプライアンスから Google Cloud Storage に移行する必要がありますがアウトバウンド ネットワークの容量が 20 Mb/秒に制限されています。
このデータをどのようにして Google Cloud Storage に移行する必要あるでしょうか?
- A. Google Transfer Appliance を使用してデータを Google CloudStorage にコピーします。
- B. gsutil cp を使用して Google Cloud Storage にアップロードされているコンテンツを圧縮します。
- C. 履歴データのプライベート URL を作成し、Google Cloud Storage Transfer Service を使用してデータを Google Cloud Storage にコピーします。
- D. gsutil cp と一緒にrickle または ionice を使用して gsutil が使用する帯域幅の量を20 Mb/秒未満に制限し、本番トラフィックに干渉しないようにします。
Correct Answer: A
Question 23
社内のさまざまな部門に Google BigQuery へのアクセスを設定する必要があります。
– 各部門は自社のデータにのみアクセスできるようにする必要があること。
– 各部門にはテーブルを作成して更新し、チームに提供することができる必要がある1つ以上のリードであること。
– 各部門にはデータアナリストがいて、データの照会はできるがデータの修正はできない必要があること。
Google BigQuery でデータへのアクセスをどのように設定すればよいのでしょうか?
- A. 部門ごとにデータセットを作成します。 部門リーダーにOWNER の役割を割り当て、データアナリストにデータセットに対するWRITER の役割を割り当てます。
- B. 各部門のデータセットを作成します。 部門リーダーにWRITER の役割を割り当て、データアナリストにデータセットのREADER の役割を割り当てます。
- C. 部門ごとにテーブルを作成します。 部門リーダーにOWNER の役割を割り当て、データアナリストにテーブルが含まれるプロジェクトのるWRITER 役割を割り当てます。
- D. 部門ごとにテーブルを作成します。 部門リーダーにWRITER の役割を割り当て、データアナリストにテーブルが含まれるプロジェクトのREADER の役割を割り当てます。
Correct Answer: B
Reference contents:
– 基本ロールと権限 #データセットの基本ロール | BigQuery
Question 24
ソーシャルメディアの投稿を Google BigQuery に 1分間に 1万件のメッセージをほぼリアルタイムで保存し、分析する必要があります。
最初は個々の投稿にストリーミング挿入を使用するようにアプリケーションを設計します。アプリケーションはストリーミング挿入の直後にデータ集計も実行します。ストリーミング挿入後のクエリは強い一貫性を示さず、クエリからのレポートは飛行中のデータを見逃している可能性があることがわかります。
アプリケーションのデザインを調整するにはどうすればよいでしょうか?
- A. 蓄積されたデータを 2分ごとに読み込むようにアプリケーションを書き直します。
- B. ストリーミング挿入コードを個々のメッセージのバッチロードに変換します。
- C. 元のメッセージをGoogle Cloud SQL に読み込み、ストリーミング挿入を通して 1時間ごとにテーブルを Google BigQuery にエクスポートします。
- D. ストリーミング挿入後のデータ可用性の平均レイテンシを推定し、常に 2倍の時間を待ってからクエリを実行します。
Correct Answer: D
Question 25
株式取引を保存するデータベースと調整可能な時間ウィンドウで特定の会社の平均株価を取得するアプリケーションを操作します。
データは GoogleCloud Bigtable に保存され、株式取引の日時が行キーの先頭になります。アプリケーションには何千もの同時ユーザーがいて、在庫が増えるにつれてパフォーマンスが低下し始めていることに気がづきました。
アプリケーションのパフォーマンスを向上させるために何をすべきですか?
- A. Google Cloud Bigtable テーブルの行キー構文を変更して銘柄記号で始まるようにします。
- B. Google Cloud Bigtable テーブルの行キー構文を変更して 1秒あたりの乱数で始まるようにします。
- C. データ パイプラインを変更して株式取引の保存に Google BigQuery を使用するようにし、アプリケーションを更新します。
- D. Google Cloud Dataflow を使用して Google Cloud Storage のAvroファイルに毎日の株式取引のサマリーを書き込みます。Google Cloud Storage と Google Cloud Bigtable から読み込んでレスポンスを計算するようにアプリケーションをアップデートします。
Correct Answer: A
Question 26
物流会社を経営しており、車両ベースのセンサーのイベント配信の信頼性を向上させたいと考えています。
顧客はこれらのイベントを捕捉するために世界中で小規模なデータセンターを運営していますが、イベント収集インフラストラクチャからイベント処理インフラストラクチャへの接続性を提供する専用線は予測不可能な遅延を伴う信頼性の低いものとなっています。最も費用効果の高い方法でこの問題に対処したいと考えています。
どうすればよいのでしょうか?
- A. イベントをバッファリングするためにデータセンターに小さなKafka クラスタを配置します。
- B. データ取得デバイスに Google Cloud Pub/Sub にデータを公開させます。
- C. すべてのリモート データセンターと Google の間に Google Cloud Interconnect を確立します。
- D. セッション ウィンドウですべてのデータを集約する Google Cloud Dataflow パイプラインを書きます。
Correct Answer: B
Question 27
通常 約 5,000件/秒のメッセージを受信するApache Kafka を中心に構築されたIoT パイプラインを運用します。
Google Cloud Platform を使用して 1時間の移動平均が毎秒 4,000 メッセージを下回るとすぐにアラートを作成したいと考えています。
何をすべきでしょうか?
- A. Kafka IO を使用して Google Cloud Dataflow でデータのストリームを消費します。5分ごとに 1時間のスライドタイム ウィンドウを設定します。ウィンドウが閉じたときの平均値を計算し、平均値が 4,000メッセージ未満の場合はアラートを送信します。
- B. Kafka IO を使用して Google Cloud Dataflow でデータのストリームを消費します。1時間の固定時間ウィンドウを設定します。ウィンドウが閉じたときの平均値を計算し、平均値が 4,000 メッセージ未満の場合はアラートを送信する。
- C. Kafka Connect を使用してKafka メッセージキューを Google Cloud Pub/Sub にリンクします。Google Cloud Dataflow テンプレートを使用して Google Cloud Pub/Sub から Google Cloud Bigtable にメッセージを書き込みます。Google Cloud Scheduler を使用して 1 時間ごとにスクリプトを実行し、直近の 1 時間で Google Cloud Bigtable に作成された行の数をカウントします。その数が 4,000 を下回った場合はアラートを送信します。
- D. Kafka Connect を使用してKafka メッセージキューを Google Cloud Pub/Sub にリンクします。Google Cloud Dataflow テンプレートを使用して Google Cloud Pub/Sub から Google BigQuery にメッセージを書き込みます。Google Cloud Scheduler を使用して 5 分ごとにスクリプトを実行し、過去 1時間に Google BigQuery で作成された行数をカウントします。その数が 4,000を下回った場合はアラートを送信します。
Correct Answer: A
Reference contents:
– 外部でホストされている Kafka からのメッセージを Cloud Dataflow を使用して処理する
Question 28
MySQL を使用して Google Cloud SQL を導入する予定です。
ゾーン障害が発生した場合に高可用性を確保する必要があります。
何をすべきでしょうか?
- A. 1つのゾーンに Google Cloud SQL インスタンスを作成して同じリージョン内の別のゾーンにフェイルオーバー レプリカを作成します。
- B. 1つのゾーンに Google Cloud SQL インスタンスを作成して同じリージョン内の別のゾーンに読み取りレプリカを作成します。
- C. 1つのゾーンに Google Cloud SQL インスタンスを作成して別のリージョン内のゾーンに外部読み取りレプリカを作成します。
- D. あるリージョン内に Google Cloud SQL インスタンスを作成して同じリージョン内にある Google Cloud Storage バケットへの自動バックアップを作成します。
Correct Answer: A
Reference contents:
– 高可用性構成の概要 | Cloud SQL for MySQL
Question 29
サードパーティから毎月CSV 形式のデータファイルが送られてきます。
このデータをクリーンアップする必要がありますが 3ヶ月ごとにファイルのスキーマが変更されます。
これらの変換を実装するための要件は以下の通りです。
– 変換をスケジュール通りに実行すること。
– 開発者以外のアナリストがトランスフォームを変更できるようにすること。
– 変換を設計するためのグラフィカルなツールを提供すること。
何をすべきでしょうか?
- A. Google Cloud Dataprep を使用して変換レシピを構築・維持してスケジュールに沿って実行します。
- B. 各月のCSV データを Google BigQuery に読み込み、SQL クエリを記述してデータを標準スキーマに変換します。変換したテーブルをSQL クエリと一緒にマージします。
- C. アナリストがPython で Google Cloud Dataflow パイプラインを作成して変換を実行できるようにします。Python コードはリビジョン管理システムに保存して入力データのスキーマが変更されたときに変更される必要があります。
- D. Google Cloud Dataproc のApache Spark を使用してデータフレームを作成する前にCSV ファイルのスキーマを推測します。その後、データを Google Cloud Storage に書き出して Google BigQuery に読み込みする前にSpark SQL で変換を実装します。
Correct Answer: A
Question 30
Kafka クラスタを経由してRedis クラスタにストリーミングデータをインポートするように設定します。
両方のクラスタは Google Compute Engine インスタンスで動作しています。
必要に応じて作成、回転、破棄できる暗号化キーを使用して静止時のデータを暗号化する必要があります。
何をすべきでしょうか?
- A. 専用のサービス アカウントを作成し、保存時に暗号化を使用して API サービス呼び出しの一部として Google Compute Engine クラスタ インスタンスに保存されているデータを参照します。
- B. Google Cloud Key Management Service で暗号鍵を作成します。それらのキーを使用して Google Compute Engine クラスタ インスタンスのすべてのデータを暗号化します。
- C. 暗号鍵をローカルに作成します。暗号鍵を Google Cloud Key Management Service にアップロードします。これらの暗号鍵を使用してすべての Google Compute Engine クラスタ インスタンスでデータを暗号化します。
- D. Google Cloud Key Management Service で暗号鍵を作成します。Google Compute Engine クラスタ インスタンス内のデータにアクセスする際にAPI サービス呼び出しでこれらのキーを参照します。
Correct Answer: B
Reference contents:
– Cloud KMS 鍵によるリソースの保護
Question 31
履歴データを Google Cloud Storage に保存しています。
履歴データに対して分析を行う必要があり、無効なデータエントリを検出してプログラミングやSQL の知識を必要としないデータ変換を実行するためのソリューションを使用したい。
何をすべきでしょうか?
- A. Google Cloud Dataflow with Beam を使用してエラーを検出して変換を実行します。
- B. Google Cloud Dataprep とレシピを使用してエラーを検出して変換を実行します。
- C. Google Cloud Dataproc をHadoop ジョブで使用してエラーを検出して変換を実行します。
- D. Google BigQuery の連携テーブルをクエリで使用してエラーを検出して変換を実行します。
Correct Answer: B
Question 32
Google BigQuery のデータセットを分析に使用しています。
サードパーティ企業に同じデータセットへのアクセスを提供したいと考えており、データ共有のコストを低く抑え、データが最新であることを保証する必要があります。
どのソリューションを選択すべきでしょうか?
- A. Google BigQuery テーブルに承認済みビューを作成してデータアクセスを制御してそのビューへのアクセス権をサードパーティ企業に提供します。
- B. Google Cloud Scheduler を使用して定期的に Google Cloud Storage にデータをエクスポートしてそのバケットへのアクセス権をサードパーティ企業に提供します。
- C. Google BigQuery で共有する関連データを含む別のデータセットを作成してサードパーティ企業にその新しいデータセットへのアクセス権を提供します。
- D. 頻繁な時間間隔でデータを読み取り、関連する Google BigQuery データセットまたは Google Cloud Storage バケットに書き込み、サードパーティ企業が使用できるようにする Google Cloud Dataflow ジョブを作成します。
Correct Answer: A
Question 33
一元化された分析プラットフォームとして Google BigQuery を使用しています。
新しいデータは毎日読み込まれ、ETL パプラインによって元のデータを変更してエンドユーザー向けに準備されます。ETL パイプラインは定期的に修正され、エラーが発生することがありますが 2週間後になって初めてエラーが検出されることもあります。このようなエラーから回復する方法を提供する必要があり、バックアップはストレージコストを考慮して最適化する必要があります。
Google BigQuery でデータを整理してバックアップをどのように保存しておくべきでしょうか。
- A. データを1つのテーブルに整理して GoogleBigQuery データをエクスポートして圧縮してGoogleCloudStorageに保存します。
- B. データを月ごとに別々のテーブルに整理してデータを圧縮してエクスポートし、Google Cloud Storage に保存します。
- C. データを月ごとに別々のテーブルに整理して Google BigQuery の別々のデータセットにデータを複製します。
- D. データを月ごとに別々のテーブルに整理してスナップショット デコレーターを使用してテーブルを破損する前の時間に復元します。
Correct Answer: B
Reference contents:
– データの障害復旧シナリオ #Google Cloud のマネージド データベース サービス | アーキテクチャ
Question 34
Google Cloud Dataprep を使用して Google BigQuery テーブルのデータサンプルにレシピを作成しました。
実行時間が可変のロードジョブが完了した後、同じスキーマで毎日アップロードされるデータでこのレシピを再利用したいとします。
どうすればいいのでしょうか?
- A. Google Cloud Dataprep でcron スケジュールを作成します。
- B. Google App Engine のcron ジョブを作成して Google Cloud Dataprep ジョブの実行をスケジュールします。
- C. レシピを Google Cloud Dataprep テンプレートとしてエクスポートして Google Cloud Schedulerでジョブを作成します。
- D. Google Cloud Dataprep ジョブを Google Cloud Dataflow テンプレートとしてエクスポートして Google Cloud Composer ジョブに組み込みます。
Correct Answer: D
Reference contents:
– Cloud Composer で Cloud Dataprep ジョブをオーケストレートする方法
– Running Cloud Dataprep jobs on Cloud Dataflow for more control
Question 35
毎日何十万ものソーシャルメディアの投稿を最小のコストで最小限のステップで分析したいと考えています。
要件は次になります。
– 投稿を 1日 1回バッチロードして Google Cloud Natural Language API を利用して実行すること。
– 投稿からトピックと感情を抽出すること。
– アーカイブと再処理のために生の投稿を保存する必要すること。
– ダッシュボードを作成して、組織内外の人々と共有する。
分析を実行するためにAPI から抽出したデータと履歴アーカイブのための生のソーシャルメディア投稿の両方を保存する必要があります。
何をすべきでしょうか?
- A. ソーシャルメディアの投稿とAPI から抽出したデータを Google BigQuery に保存します。
- B. ソーシャルメディアの投稿とAPI から抽出したデータを Google Cloud SQL に保存します。
- C. 生のソーシャルメディア投稿を Google Cloud Storage に保存してAPI から抽出したデータを Google BigQuery に書き込みます。
- D. ソーシャルメディアの投稿をソースから直接API にフィードしてAPI から抽出したデータを Google BigQuery に書き込みます。
Correct Answer: C
Question 36
Google Cloud Storage にデータをアーカイブしたいと考えています。
一部のデータは非常に機密性が高いため、Trust No One(TNO)アプローチを使用してデータを暗号化し、クラウド プロバイダのスタッフがデータを復号化できないようにします。
どうすればいいのでしょうか?
- A. gcloud kms keys を使用して対称鍵を作成します。次に gcloud kms encrypt を使用して各アーカイブ ファイルを鍵と固有の追加認証データ(AAD)で暗号化します。gsutil cp を使用して暗号化された各ファイルを Google Cloud Storage バケットにアップロードして AAD を Google Cloud の外部に保持します。
- B. gcloud kms の鍵を使用して対称鍵を作成します。次に gcloud kms encrypt を使用して各アーカイブ ファイルをその鍵で暗号化します。gsutil cp を使用して暗号化された各ファイルを Google Cloud Storage バケットにアップロードします。暗号化に使用していた鍵を手動で破棄し、鍵を一度ローテンションさせます。
- C. .boto 設定ファイルに顧客指定の暗号鍵(CSEK)を指定します。gsutil cpを使用して各アーカイブ ファイルを Google Cloud Storage バケットにアップロードします。シークレットの永続ストレージとして CSEKを Cloud Memorystore に保存します。
- D. .boto 設定ファイルに顧客指定の暗号鍵(CSEK)を指定します。gsutil cp を使用して各アーカイブ ファイルを Google Cloud Storage バケットにアップロードします。CSEK をセキュリティチームのみがアクセスできる別のプロジェクトに保存します。
Correct Answer: D
Reference contents:
– 追加認証データ | Cloud KMS ドキュメント
Question 37
Google Cloud で実行されている複数ステップのデータ パイプラインの実行を自動化したいとします。
パイプラインには互いに複数の依存関係を持つ Google Cloud Dataproc と Google Cloud Dataflow ジョブが含まれています。可能な限りマネージドサービスを使用する必要があり、パイプラインは毎日実行されます。
どのツールを使うべきでしょうか?
- A. cron
- B. Google Cloud Composer
- C. Google Cloud Scheduler
- D. Google Cloud Dataproc ワークフロー テンプレート
Correct Answer: B
Question 38
データレイクとして管理されたHadoopシステムを構築したいとします。
データ変換プロセスは一連のHadoop ジョブを順番に実行することで構成されています。ストレージとコンピュートを分離する設計を達成するために Google Cloud Storage コネクタを使用してすべての入力データ、出力データ、中間データを保存することにしました。しかし、1つのHadoop ジョブがオンプレミスのBare Metal Hadoop 環境(8コアノード、100 GB RAM)と比較して Google Cloud Dataproc を使用して非常に遅く実行されていることに気づきました。分析によると、この特定のHadoop ジョブはディスク I/O を多用しており、この問題を解決したいと思います。
どうすればよいでしょうか?
- A. Hadoop クラスタに十分なメモリを割り当て、その特定のHadoop ジョブの中間データをメモリに保持できるようにします。
- B. Hadoop クラスタに十分な永続ディスクスペースを割り当て、その特定のHadoop ジョブの中間データをネイティブ HDFS上に保存します。
- C. 各インスタンスのネットワーク帯域幅がスケールアップできるように、Hadoopクラスタの仮想マシンインスタンスのCPU コアをより多く割り当てます。
- D. 追加のネットワークインター フェイス カード(NIC)を割り当て、Google Cloud Storage で作業する際に複合スループットを使用するようにオペレーティング システムでリンク アグリゲーションを構成します。
Correct Answer: B
Question 39
オンプレミスのHadoop システムを Google Cloud Dataproc に移行を計画しています。
使用しているツールはHive がメインでデータ形式はOptimized Row Columnar(ORC)です。すべてのORC ファイルが Google Cloud Storage バケットに正常にコピーされました。パフォーマンスを最大化するためには一部のデータをクラスタのローカル分散ファイル システム(HDFS)にレプリケートする必要があります。
Google Cloud Dataproc でHive の使用を開始するにはどうすればいいでしょうか?(2つ選択してください)
- A. gsutil ユーティリティを実行して Google Cloud Storage バケットからHDFS にすべてのORC ファイルを転送します。ハイブのテーブルをローカルにマウントします。
- B. gsutil ユーティリティを実行して Google Cloud Storage バケットからすべてのORC ファイルを Google Cloud Dataproc クラスタの任意のノードに転送します。Hive テーブルをローカルにマウントします。
- C. gsutil ユーティリティを実行して Google Cloud Storage バケットからすべてのORC ファイルを Google Cloud Dataproc クラスタのマスター ノードに転送します。その後、Hadoop ユーティリティを実行してそれらを HDFS にコピーします。HDFS からHive テーブルをマウントします。
- D. Hadoop の Google Cloud Storage コネクタを活用してORC ファイルを外部 Hive テーブルとしてマウントします。外部のHive テーブルをネイティブのテーブルに複製します。
- E. ORC ファイルを Google BigQuery に読み込みします。Hadoop 用の Google BigQuery コネクタを活用して Google BigQuery テーブルを外部 Hive テーブルとしてマウントします。外部のHive テーブルをネイティブのものにレプリケートします。
Correct Answer: D、E
Question 40
Google Cloud Platform で動作するPOS アプリケーションで決済処理を行いたいと考えています。
ユーザー数は飛躍的に増加する可能性があるが、インフラストラクチャのスケーリングを管理したくありません。
どの GCP データベース サービスを使用するべきでしょうか?
- A. Google Cloud SQL
- B. Google BigQuery
- C. Google Cloud Bigtable
- D. Google Cloud Datastore
Correct Answer: A
Question 41
組織サンプルに関する情報のデータベースを使用して将来の組織サンプルを正常か突然変異のどちらかに分類したいと考えています。
組織サンプルを分類するための教師なし異常検出法を評価しています。
この方法をサポートする特徴はどれでしょうか?(2つ選択してください)
- A. 正常なサンプルと比較して突然変異の発生は変異の発生はほとんどありません。
- B. データベースには正常なサンプルと変異したサンプルの両方がほぼ同じように出現します。
- C. 将来の突然変異はデータベース内の突然変異サンプルとは異なる特徴を持つことが予想されます。
- D. 将来の突然変異がデータベース内の変異したサンプルと同様の機能があると予想されます。
- E. データベースにはサンプルが変異してデータベースで正常なラベルがすでにあります。
Correct Answer: A、D
Question 42
Google BigQuery テーブルをデータシンクとして使用したいとします。
どの書き込みモードでGoogle BigQuery をシンクとして使用できますか?
- A. バッチとストリーミングの両方。
- B. Google BigQueryはシンクとしては使えない。
- C. バッチのみ。
- D. ストリーミングのみ。
Correct Answer: A
バッチ モー ドで Google BigQueryIO.Write 変換フォームを適用して単一のテーブルに書き込む場合、Google Cloud Dataflow は Google BigQuery のロード ジョブを呼び出します。Google BigQueryIO.Write 変換フォームをストリーミング モードまたはバッチ モードで宛先テーブルを指定する関数を使用して適用すると Google Cloud Dataflow は Google BigQuery のストリーミング挿入を使用します。
Reference contents:
– BigQuery I/O
Question 43
Google BigQuery の使用状況を監視するために Google Stackdriver Logging の使用を検討しています。
挿入ジョブを使用して特定のテーブルに新しいデータが追加されたときに監視ツールに即座に通知を送信する必要がありますが他のテーブルの通知を受信したくありません。
どうすればよいでしょうか?
- A. Stackdriver API を呼び出してすべてのログを一覧表示して高度なフィルタを適用します。
- B. Stackdriver Logging 管理インターフェイスで Google BigQuery へのログシンクのエクスポートを有効にします。
- C. Stackdriver Logging 管理インターフェイスで Google Cloud Pub/Sub へのログ シンク エクスポートを有効にし、監視ツールからトピックを購読します。
- D. Stackdriver API を使用して高度なログ フィルタを備えたプロジェクト シンクを作成して Google Cloud Pub/Sub にエクスポートし、監視ツールからトピックをサブスクライブします。
Correct Answer: D
Reference contents:
– ログのエクスポートの概要 | Cloud Logging
– Cloud Logging のイベントをリアルタイムで検出して対応する
Question 44
すでに付与された融資申請書とこれらの申請書が不履行(デフォルト)になっているかどうかに関する情報を含むラベル付きデータセットがあります。
クレジット申請者のデフォルト率を予測するためのモデルをトレーニングするように依頼されました。
何をするべきでしょうか?
- A. 追加のデータを収集してデータセットのサイズを増やします。
- B. クレジット デフォルト リスク スコアを予測するために線形回帰をトレーニングします。
- C. データからバイアスを取り除き、融資が断られたアプリケーションを収集する。
- D. ローンの申請者をソーシャルプロファイルと照合して機能エンジニアリングを有効にします
Correct Answer: B
Question 45
Google Cloud Pub/Sub を使用してデータ パイプラインを設定し、異常なセンサー イベントをキャプチャしています。
Google Cloud Pub/Sub のpush サブスクリプションを使用していますが、このサブスクリプションは異常なイベントが発生したときにそれを処理するために作成したカスタム HTTPS エンドポイントを呼び出します。カスタム HTTPS エンドポイントは膨大な量の重複メッセージを取得し続けています。
これらの重複メッセージの最も可能性の高い原因は何でしょうか?
- A. センサーイベントのメッセージ本文が大きすぎます。
- B. カスタム エンドポイントのSSL 証明書が古くなっています。
- C. Google Cloud Pub/Sub トピックに公開されているメッセージが多すぎます。
- D. カスタム エンドポイントが確認期限内にメッセージを確認していません。
Correct Answer: D
Reference contents:
– トラブルシューティング #重複の処理と再試行の強制 | Cloud Pub/Sub ドキュメント
Question 46
40 TB のデータを用いてモデルをトレーニングし、各地域のどの船が特定の日に配送遅延を引き起こす可能性が高いかを予測したいと考えています。
モデルは複数のソースから収集した複数の属性に基づいています。GeoJSON 形式の位置情報を含むテレメトリデータは各船から取得され、1時間ごとに読み込みされます。地域内で遅延を引き起こす可能性のある船舶の数と数を表示するダッシュボードが必要です。予測と地理空間処理のためのネイティブ機能を備えたストレージソリューションを使用したいと考えています。
どのストレージ ソリューションを使用するべきでしょうか?
- A. Google BigQuery
- B. Google Cloud Bigtable
- C. Google Cloud Datastore
- D. Google Cloud SQL for PostgreSQL
Correct Answer: A
Reference contents:
– BigQuery GIS の概要
Question 47
従業員情報を Google BigQuery で FirstName フィールドと LastName フィールドで構成される Users テーブルに保存しています。
IT 部門のメンバーがアプリケーションを構築中で Google BigQuery のスキーマとデータを変更してFirstName フィールドの値をスペースで連結したFullName フィールドと、各従業員の LastName フィールドの値で構成される FullName フィールドをアプリケーションがクエリできるようにしてほしいと依頼されました。
コストを最小限に抑えながらそのデータを利用できるようにするにはどうすればよいでしょうか?
- A. Google BigQuery でFirstName とLastName フィールドの値を連結してFullName を生成するビューを作成します。
- B. FullName という名前の新しい列をUsers テーブルに追加します。各ユーザーのFullName 列を FirstName とLastName の値を連結して更新するUPDATE ステートメントを実行します。
- C. Users テーブル全体に対して Google BigQuery をクエリして各ユーザーのFirstName 値とLastName 値を連結し、FirstName、LastName、FullName の適切な値を Google BigQuery の新しいテーブルに読み込みする Google Cloud Dataflow ジョブを作成します。
- D. Google BigQuery を使用してテーブルのデータをCSV ファイルにエクスポートします。Google Cloud Dataproc ジョブを作成してCSV ファイルを処理し、FirstName、LastName、FullName の適切な値を含む新しいCSV ファイルを出力します。Google BigQuery ロード ジョブを実行して新しい CSV ファイルを Google BigQuery に読み込みします。
Correct Answer: C
Question 48
製造会社はそれぞれが異なるサプライヤーから最大 750個の異なる部品を調達しています。
各部品ごとに平均 1,000個の例があるラベル付きデータセットを収集しました。チームは倉庫の作業員が部品の写真に基づいて入荷した部品を認識するためのアプリを実装したいと考えています。数日以内にこのアプリの最初の動作バージョン(Proof-Of-Concept)を実装したいと考えています。
何をすべきでしょうか?
- A. 既存のデータセットでGoogle Cloud Vision AutoML を使用します。
- B. Google Cloud Vision AutoML を使用してデータセットを 2回縮小します。
- C. 認識のヒントとしてカスタムラベルを提供することで Google Cloud Vision API を使用します。
- D. 転送学習技術を利用して独自の画像認識モデルをトレーニングします。
Correct Answer: A
Reference contents:
– AutoML Vision 初心者向けガイド #Vision API と AutoML のどちらのツールが適切か
Question 49
製造工場はアプリケーションのログファイルをまとめて 1日 1回 午前 2時に 1つのログファイルにまとめています。
そのログファイルを処理するために Google Cloud Dataflow ジョブを作成しました。このログファイルが 1 日 1 回できるだけ安価に処理されるようにする必要があります。
何をすべきでしょうか?
- A. 処理ジョブを変更して代わりに Google Cloud Dataproc を使用するようにします。
- B. 毎朝、出社時に Google Cloud Dataflow ジョブを手動で起動します。
- C. Google App Engine Cron サービスでcron ジョブを作成して Google Cloud Dataflow ジョブを実行します。
- D. ログデータをすぐに処理するように Google Cloud Dataflow ジョブをストリーミング ジョブとして設定します。
Correct Answer: C
Reference contents:
– cron.yaml を使用したジョブのスケジューリング
Question 50
業務システムのトランザクション データをオンプレミスのデータベースから GCP に移行する必要があります
データベースのサイズは約 20 TBです。
どのデータベースを選択するべきでしょうか?
- A. Google Cloud SQL
- B. Google Cloud Bigtable
- C. Google Cloud Spanner
- D. Google Cloud Datastore
Correct Answer: A
関連する Professional Data Engineer 模擬問題集
- Professional Data Engineer 模擬問題集(Vo.1)
- Professional Data Engineer 模擬問題集(Vo.2)
- Professional Data Engineer 模擬問題集(Vo.3)
- Professional Data Engineer 模擬問題集(Vo.4)
- Professional Data Engineer 模擬問題集(Vo.5)
Comments are closed